在当前蓬勃发展的AI领域,各大厂商都推出了自己的大语言模型服务。从而导致了我们需要高效地管理和使用这些不同的API接口。本文将介绍如何通过统一的API调用方式,简化多个大语言模型的集成过程,并提供一个具体的实施方案。 我们除了可以在官网直接使用类似ChatGPT或者Claude以外的大语言模型以外,我们也可以以开发者的角度调用不同厂商提供的大模型的API。
这种方式按正规术语来说就是API集成或模型服务集成。
简单来说就是我们可以自己封装一个自定义的AI应用,把大语言模型随时集成到我们想用的地方。
比如说,你想在你的购物网站里加入一个智能客服,或者在你的笔记软件里加入一个AI写作助手,都可以通过调用API来实现。
但是不同的模型可能提供的文档差别会很大。有的文档写得特别详细,代码示例丰富;有的可能就只有几行简单说明,让开发者很头疼。以讯飞星火为例,其API文档经常更新且存在版本兼容性问题,这对开发者来说是一个显著的挑战。
我们总不能每调用一次就重新根据文档进行编写吧?那也太浪费时间了。碰到某些无良的厂子要是文档写太烂了,就很费时费力。
所以很多人都想到了一种做法,将某个API调用格式作为统一标准只要大家的格式全部统一或者兼容就行了。这样一来,我们写好的代码,换个模型供应商也能直接用,最多改改接口地址和密钥就行了。
其实OpenAI的API格式因其设计合理性和广泛采用,已成为行业事实标准,所以拿来统一度量衡也就刚刚好了
然后就是为什么说OpenAI的格式成为了事实上的标准?OpenAI除了发布首个真正意义上的自然语言处理大模型ChatGPT以外,包括我在内的很多人也认为OpenAI的API调用方式确实是相对来说最简洁,清晰的。更重要的是在其他模型出现以前,几乎大部分的AI应用都是调用的OpenAI的API,总不能全部重构对吧?
当然他们的API设计得非常优雅
这种标准化的趋势对开发者来说是件好事,省去了很多重复劳动,也让不同模型之间的切换变得更加容易。
至于为什么说他们的API很优雅,这里我简单贴一下的OpenAI API调用代码,会在使用篇说明具体如何使用:
纯粹的Curl请求:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": true
}'
响应格式是:
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}
....
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
这里举个流式输出的例子,可以像打字机一样打出来
我们再贴一个python版(流式输出):
from openai import OpenAI
client = OpenAI(api_key="<API Key>", base_url="https://api.openai.com/v1")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
stream=True
)
for chunk in completion:
print(chunk.choices[0].delta)
python版(非流式输出):
from openai import OpenAI
client = OpenAI(api_key="<API Key>", base_url="https://api.openai.com/v1")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
非常的简洁
好了,接下来就是如何统一调用格式了。
其实基本上所有的大语言模型的API需要具备的要素都差不多
1.请求地址:
base_url="https://api.openai.com/v1"
2.访问令牌:
api_key="sk-xxxxxx"
3.预设提示词与用户消息:
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
只要确保这几个相关信息正确传递替换,把实际的请求格式统一成和OpenAI一样就行了
以上是简单介绍逻辑与背景,接下来就是具体操作
我们当然不需要手动一个一个去代码层面实现转换逻辑,现在已经有了很多开源的OpenAI接口管理与分发系统。比较受欢迎的有One-API和New-API。
这些系统就像是一个"翻译官",可以帮我们把不同平台的API格式自动转换成OpenAI的格式。
下面我们以NewAPI为例(我个人比较喜欢NewAPI,因为它的功能更丰富,维护也更活跃、样式也舒服):
先看看项目文档给出的部署方式:
# 使用 SQLite 的部署命令:
docker run --name new-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/new-api:/data calciumion/new-api:latest
# 使用 MySQL 的部署命令,在上面的基础上添加 `-e SQL_DSN="root:123456@tcp(localhost:3306)/oneapi"`,请自行修改数据库连接参数。
# 例如:
docker run --name new-api -d --restart always -p 3000:3000 -e SQL_DSN="root:123456@tcp(localhost:3306)/oneapi" -e TZ=Asia/Shanghai -v /home/ubuntu/data/new-api:/data calciumion/new-api:latest
第一次看着这些命令可能有点懵,不过别担心。其实我们只需要准备两样东西:
1.Docker环境
2.MySQL数据库(或者用SQLite也行,不过选择MySQL可以提供更可靠的持久化存储和数据备份机制)
如果不清楚Docker是什么,简单来说Docker就是一个"装应用的箱子"。它能让我们把应用程序和它所需要的所有环境打包在一起,就像是把所有东西都装在一个集装箱里。这样不管你在哪台电脑上运行这个"箱子",应用程序都能正常工作,不会出现"我的电脑上能运行,你的电脑上不行"这种情况。 打包好的箱子叫Docker镜像,在这里我们的镜像就叫:calciumion/new-api:latest
使用Docker的好处是:
1.最大限度不用操心环境配置
2.快速安装,一键启动
3.升级方便,想换版本就是换个镜像的事
4.删除也干净,不会在系统里留下各种零碎文件*
对于NewAPI这种需要长期运行的应用,我们也不太好直接部署在本地电脑,假如我们也没有服务器
那我们可以选择一些在线托管平台,来帮助我们部署这个应用,比如Render,sealos,koyeb,但是这些平台并不适合初学者,而且很麻烦,所以我今天给出的教程是基于

https://huggingface.co/
至于Mysql我们可以使用:https://sqlpub.com 提供的免费数据库
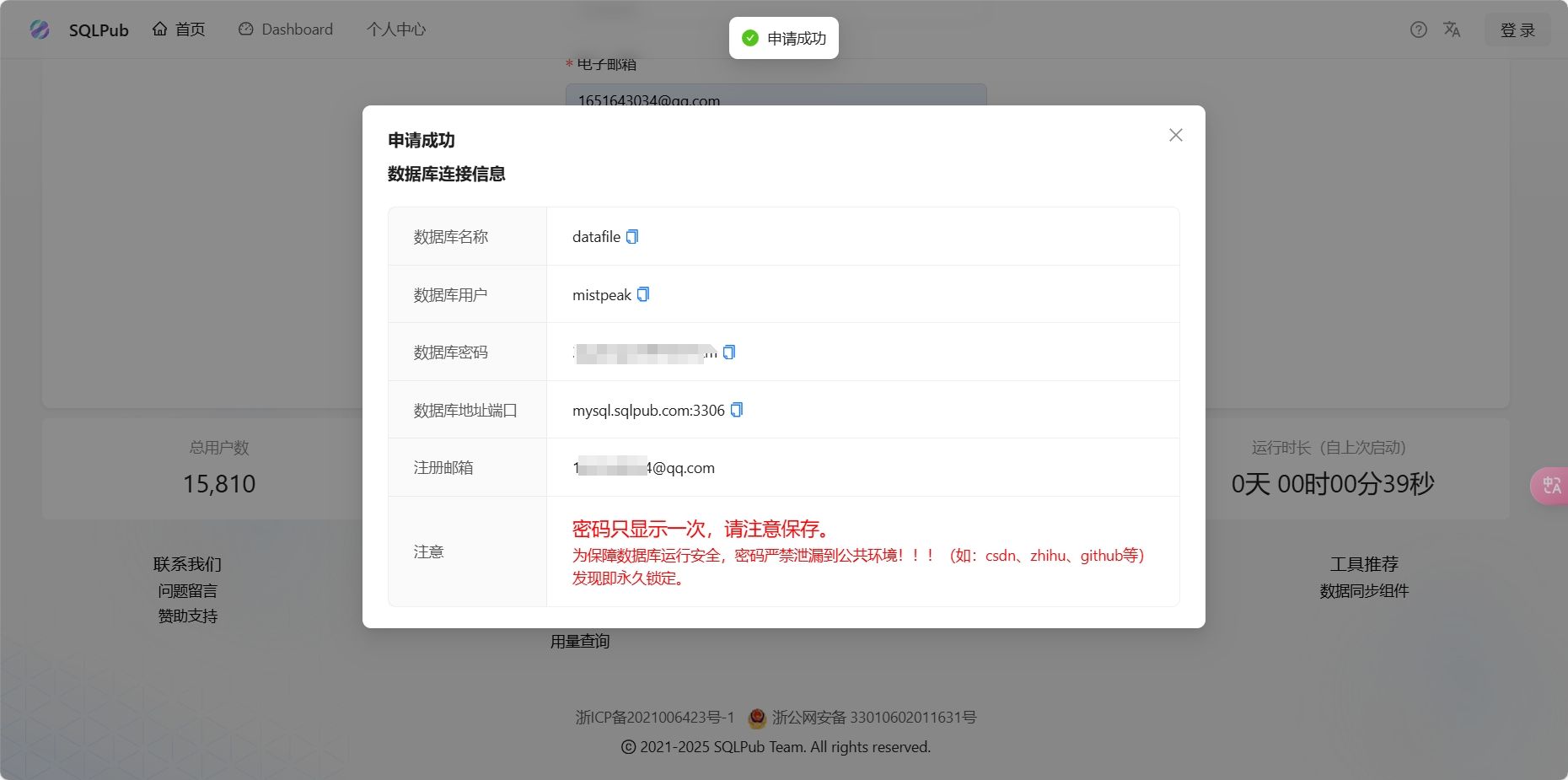
数据库名称datafile
数据库用户mistpeak
数据库密码xxxxxxxxxx
数据库地址端口mysql.sqlpub.com:3306
那我最后的环境变量:
SQL_DSN="root:123456@tcp(localhost:3306)/oneapi"
应该改成:
SQL_DSN="mistpeak:xxxxxxxxxx@tcp(mysql.sqlpub.com:3306)/datafile"
现在我们回到huggingface注册属于我们自己的huggingface账号 然后直接点开
https://huggingface.co/spaces/samlax12/NewAPI?duplicate=true&visibility=public
接下来就会看到:
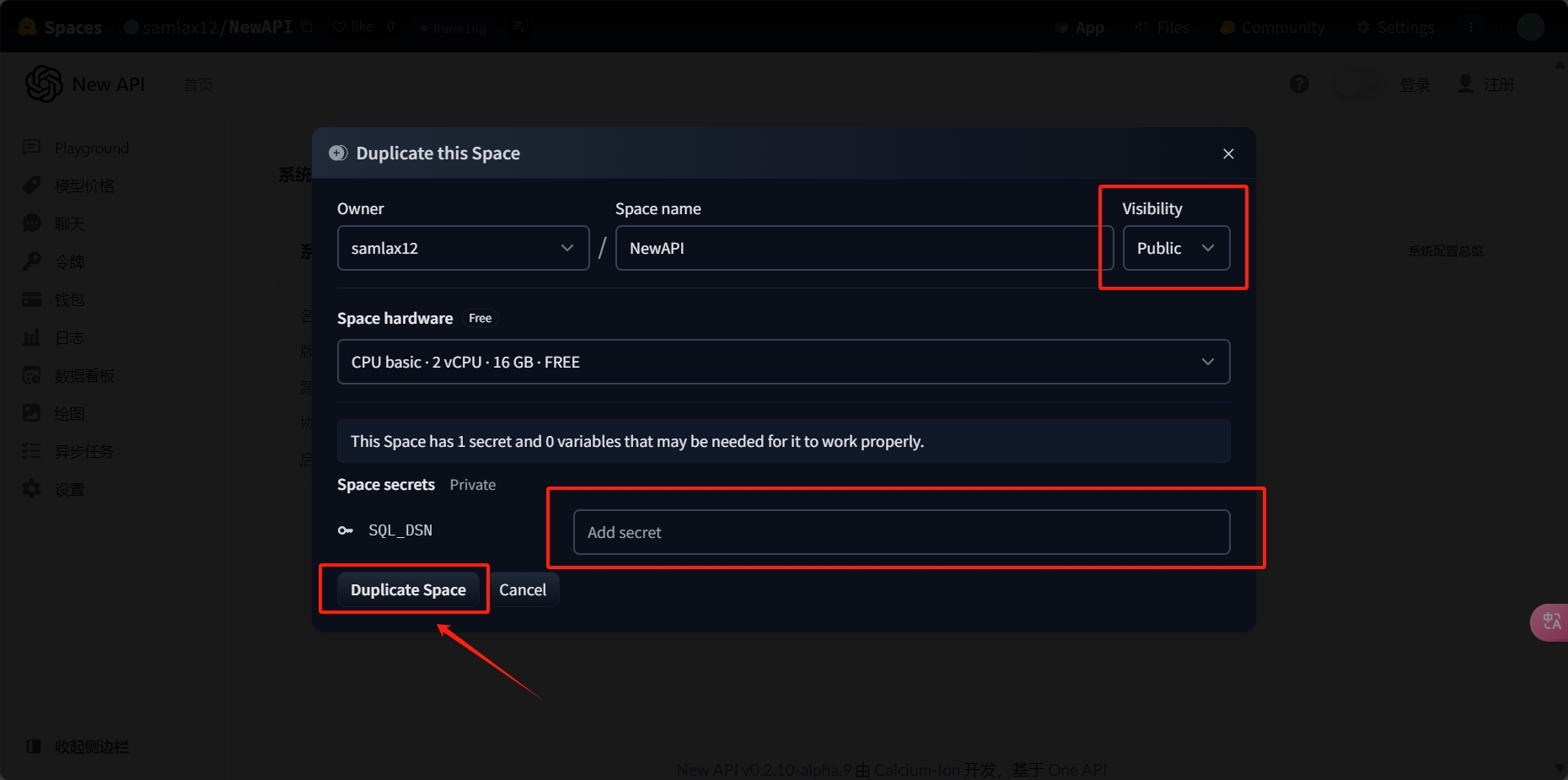
SQL_DSN="mistpeak:xxxxxxxxxx@tcp(mysql.sqlpub.com:3306)/datafile"
然后点击一下Duplicate Space按钮
最后在控制台看到Runing就意味着部署成功了
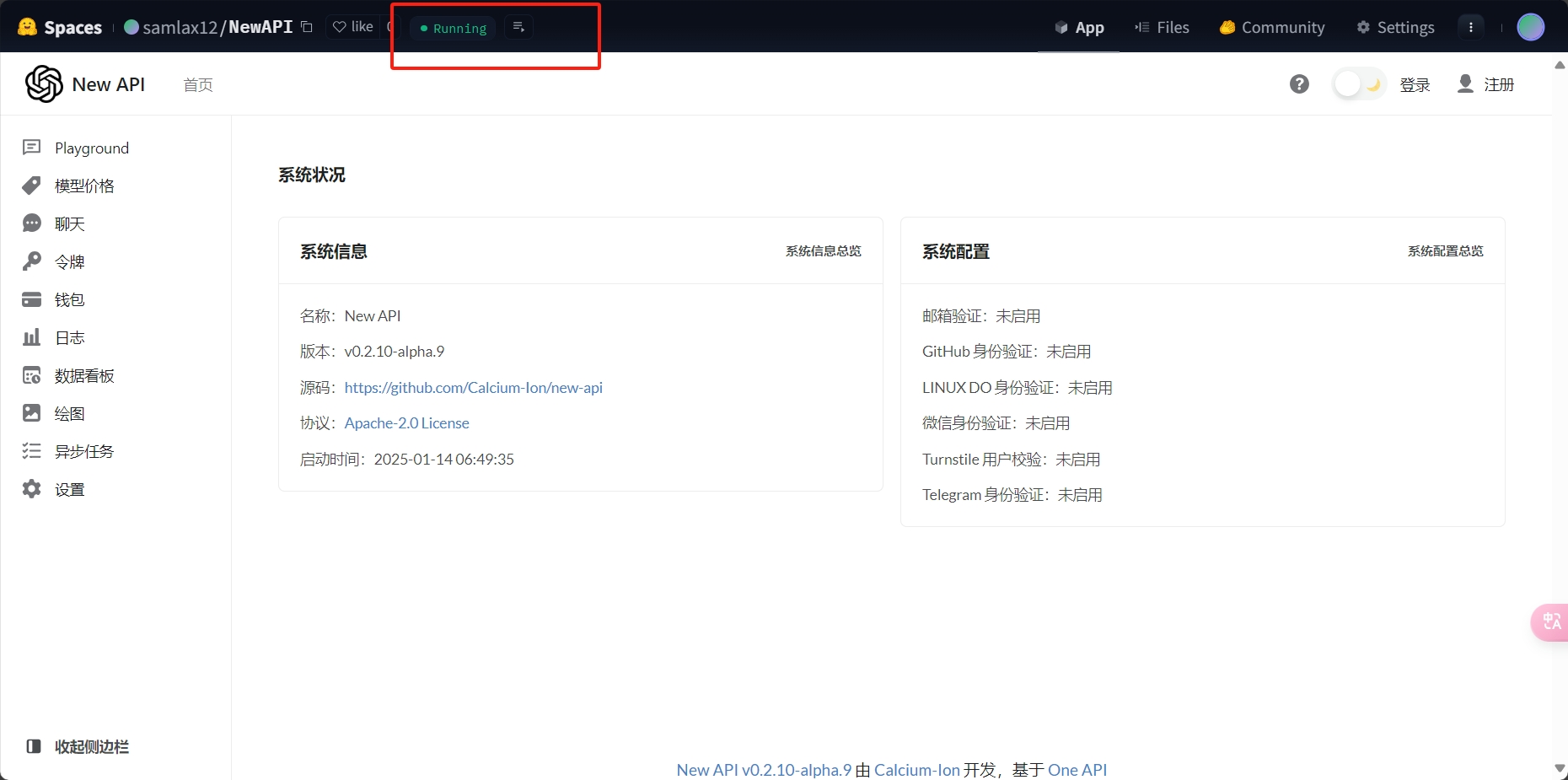
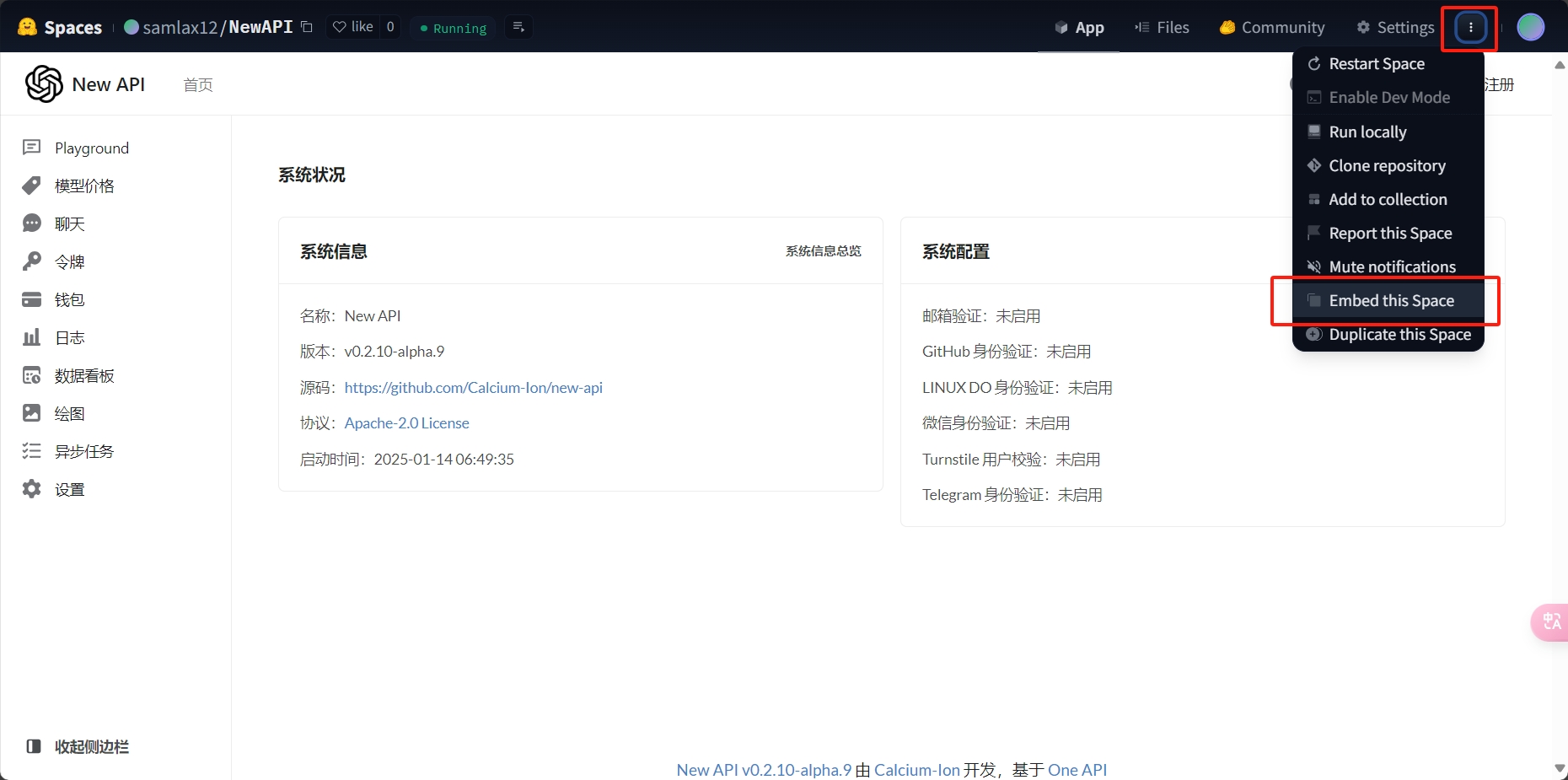
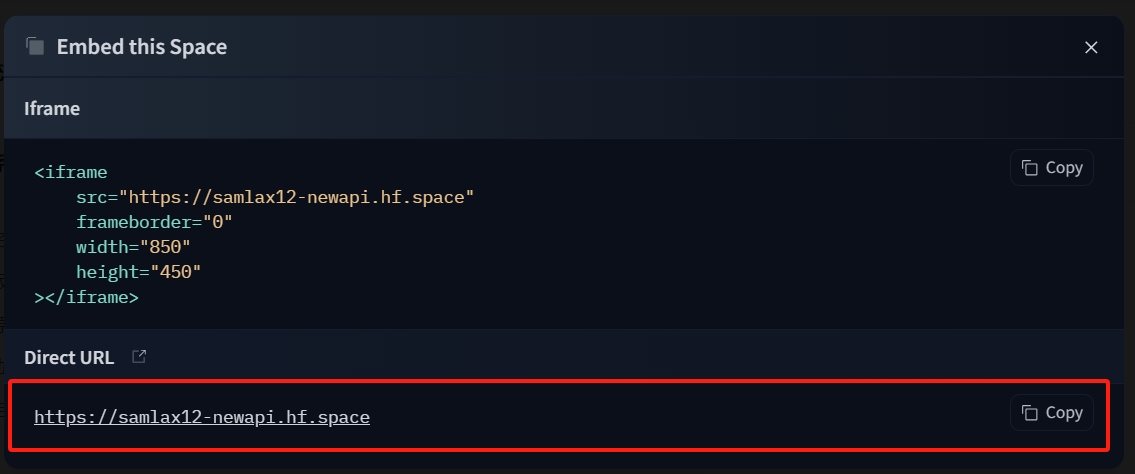
https://samlax12-newapi.hf.space
这个就是我的NewAPI服务访问地址
现在我们单独打开这个地址
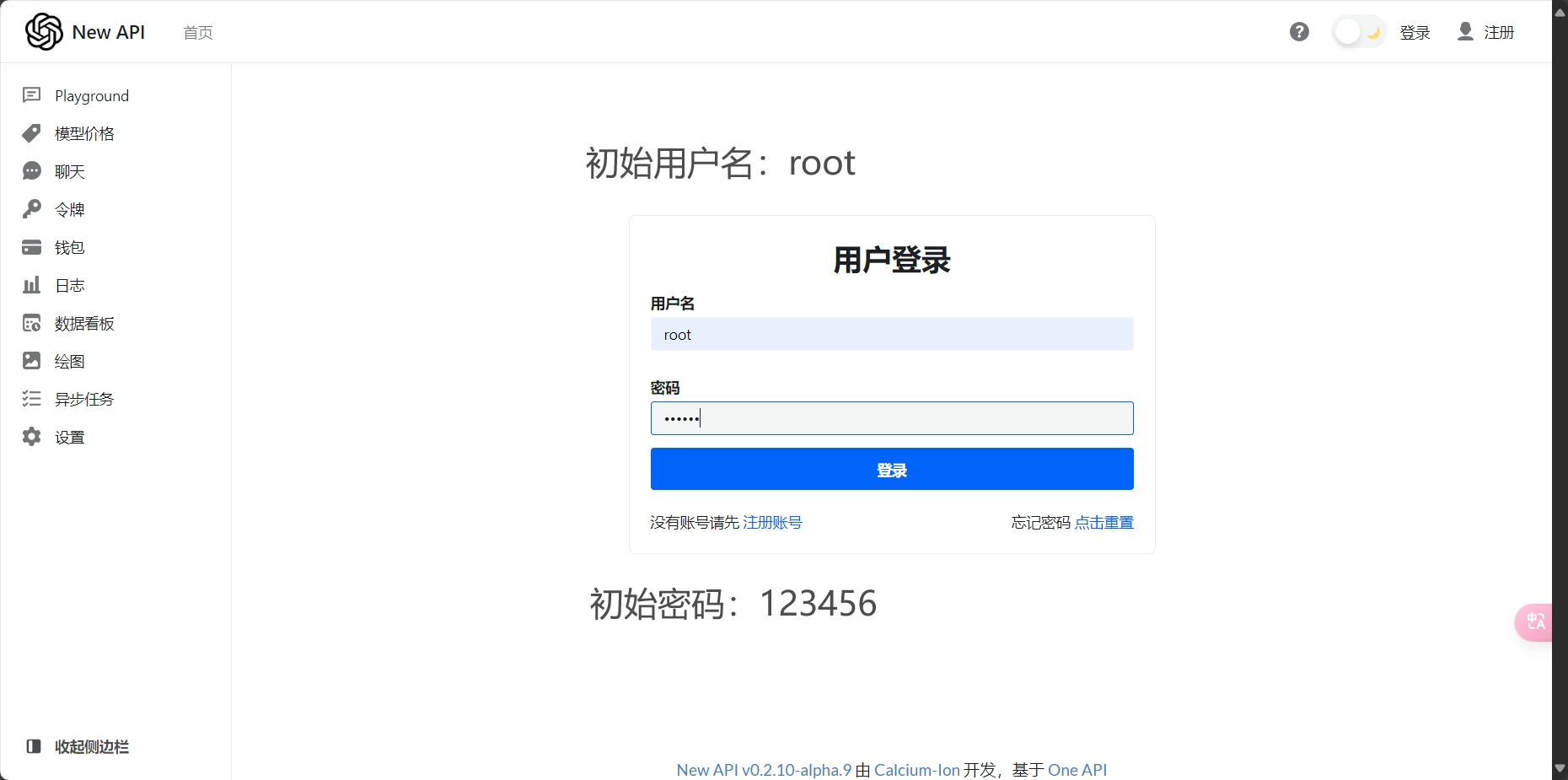
初始的用户名:root
默认密码:123456
回头在设置里面改个密码就行了
接下来就是将我们以有的其他的大模型的服务全部转换成OpenAI格式的服务就行了
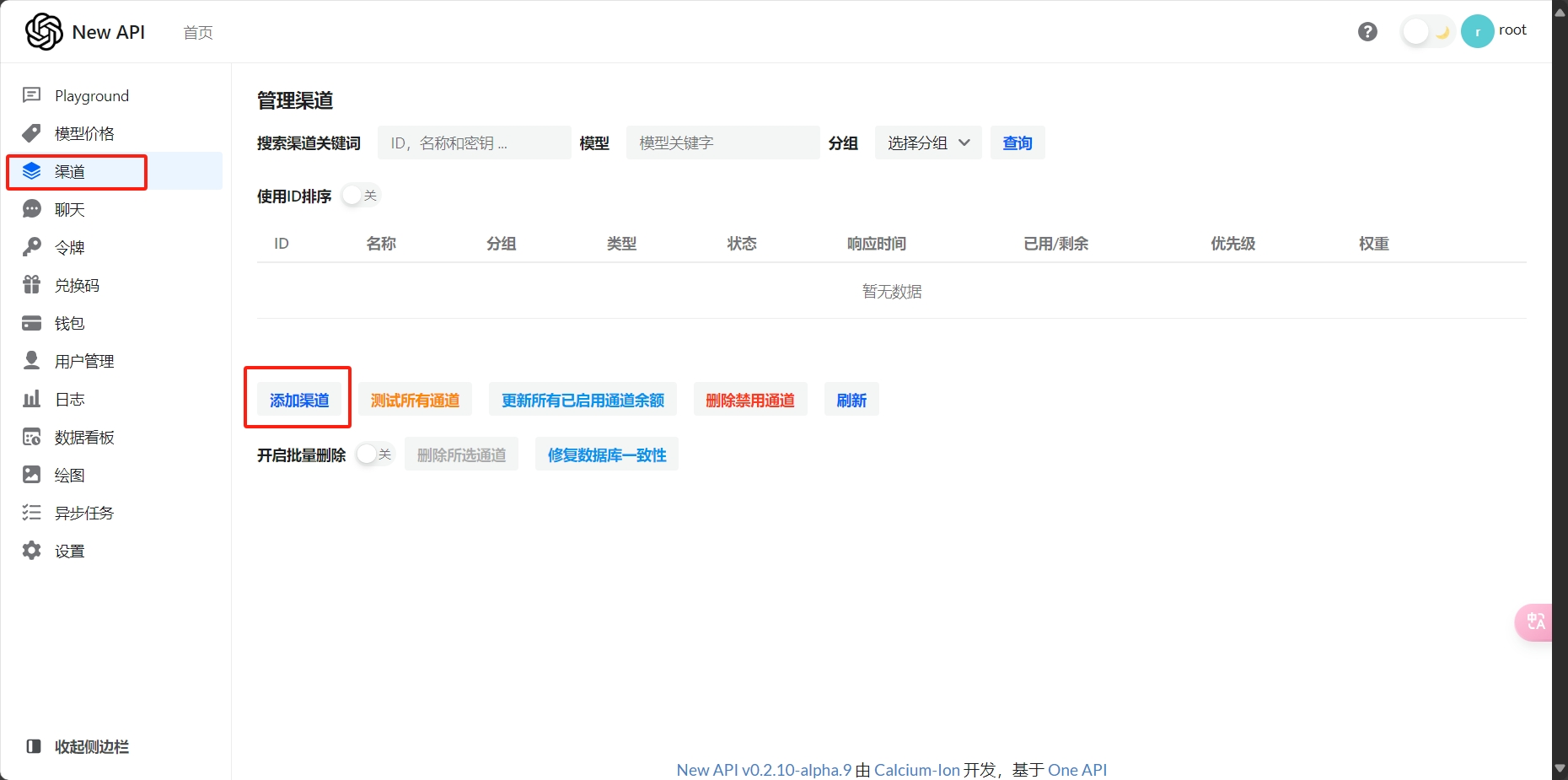
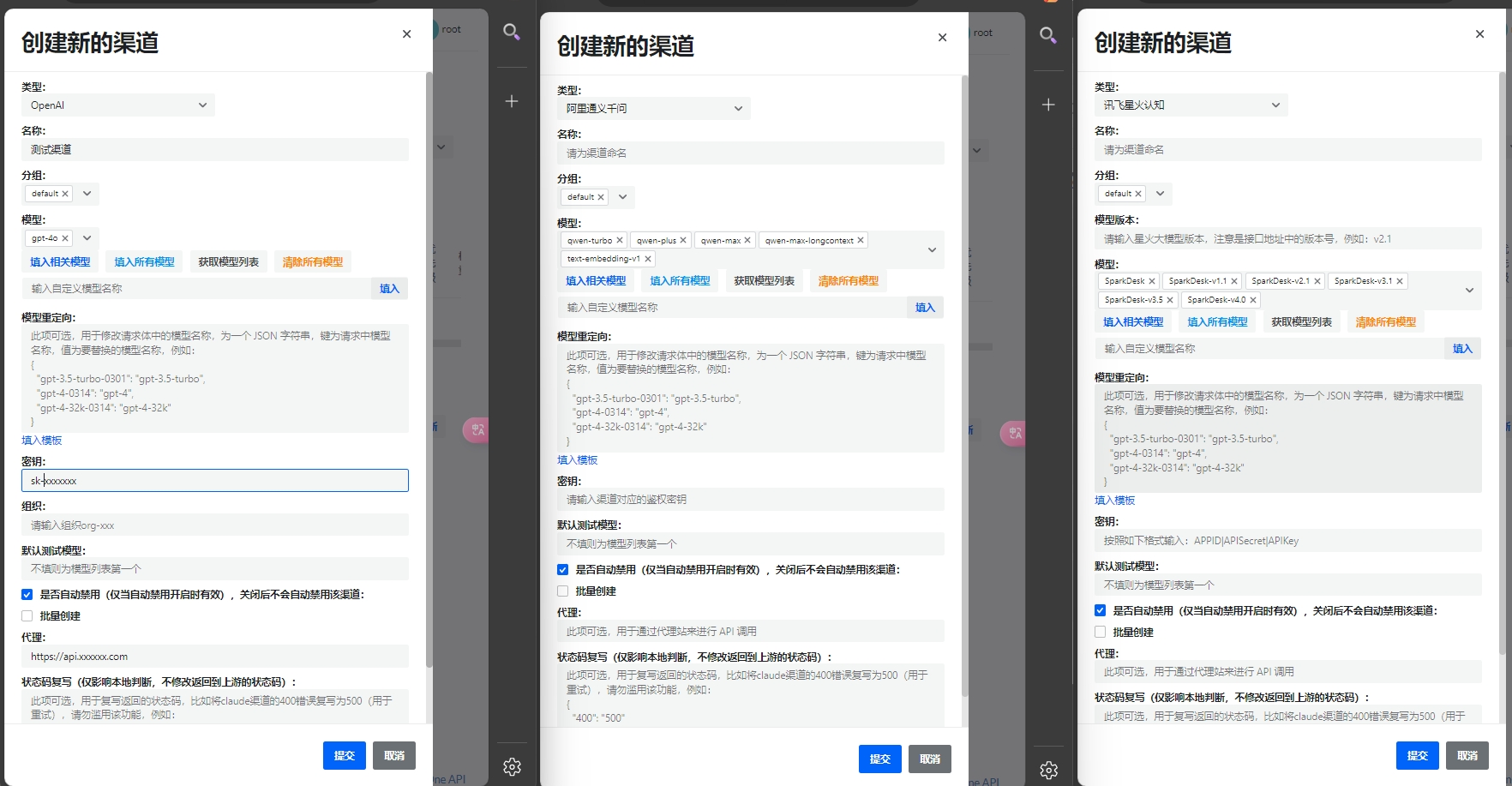
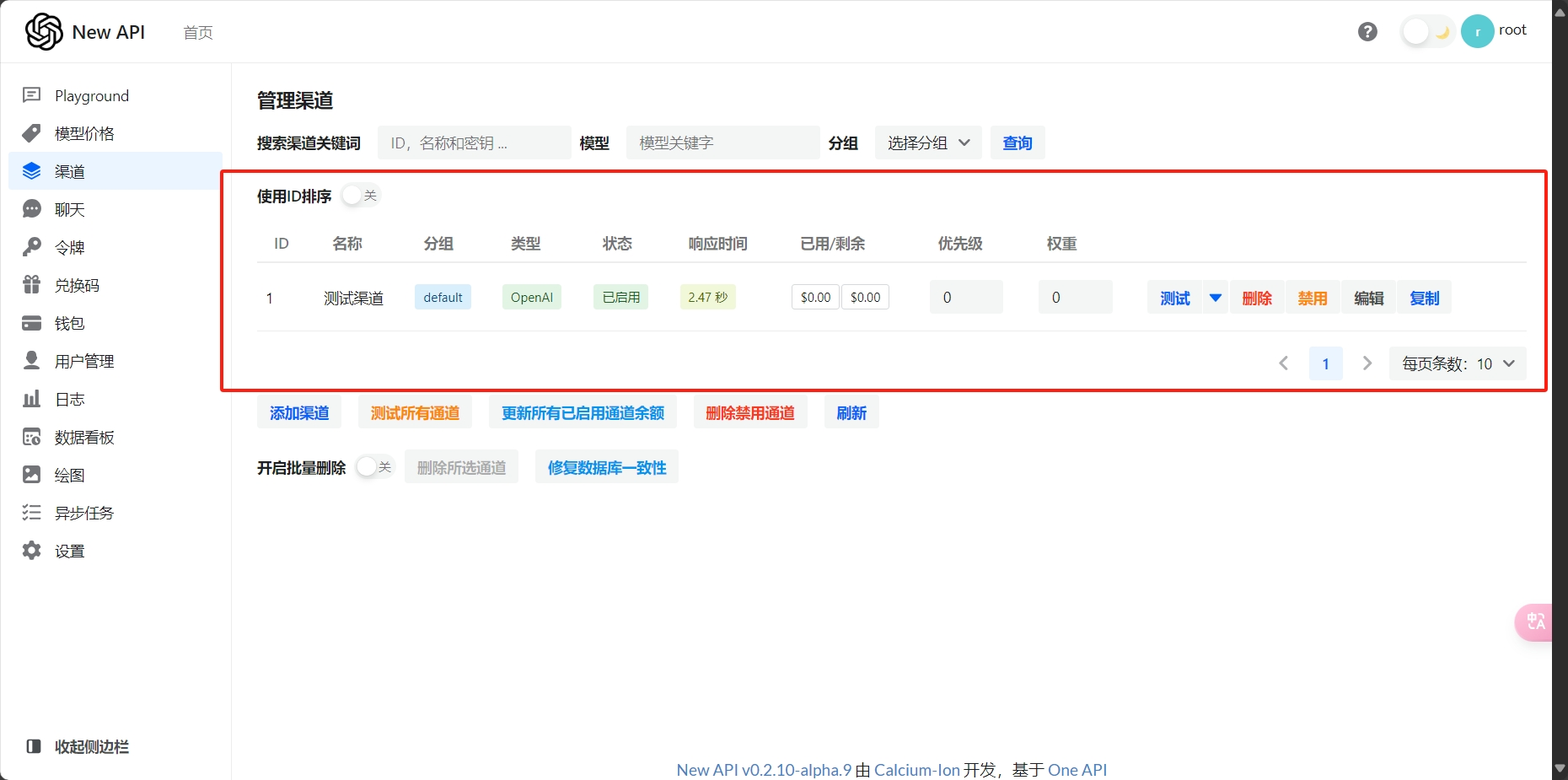
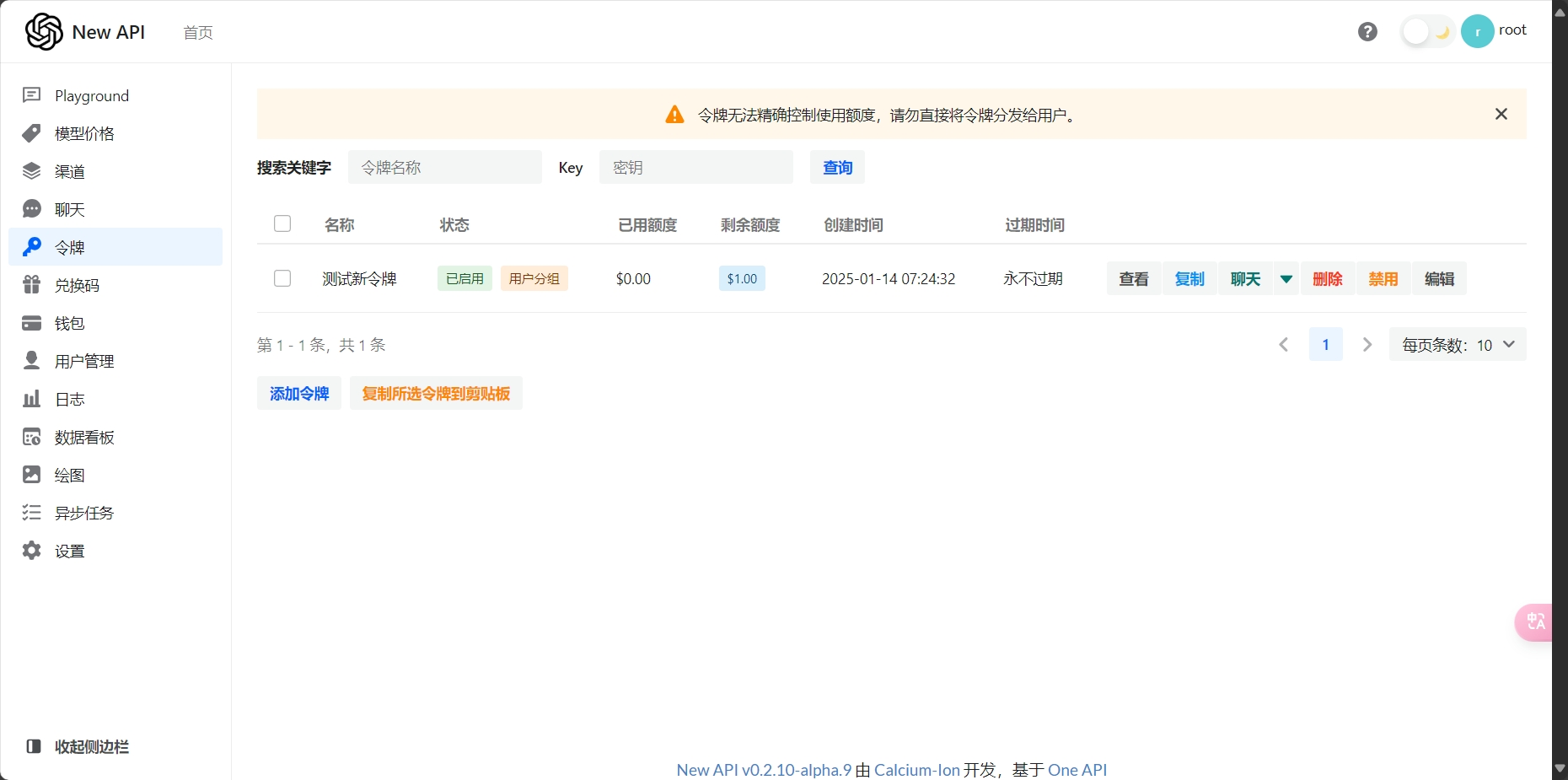
我们的New-API服务:
1.请求地址:
base_url="https://samlax12-newapi.hf.space/ai/v1"
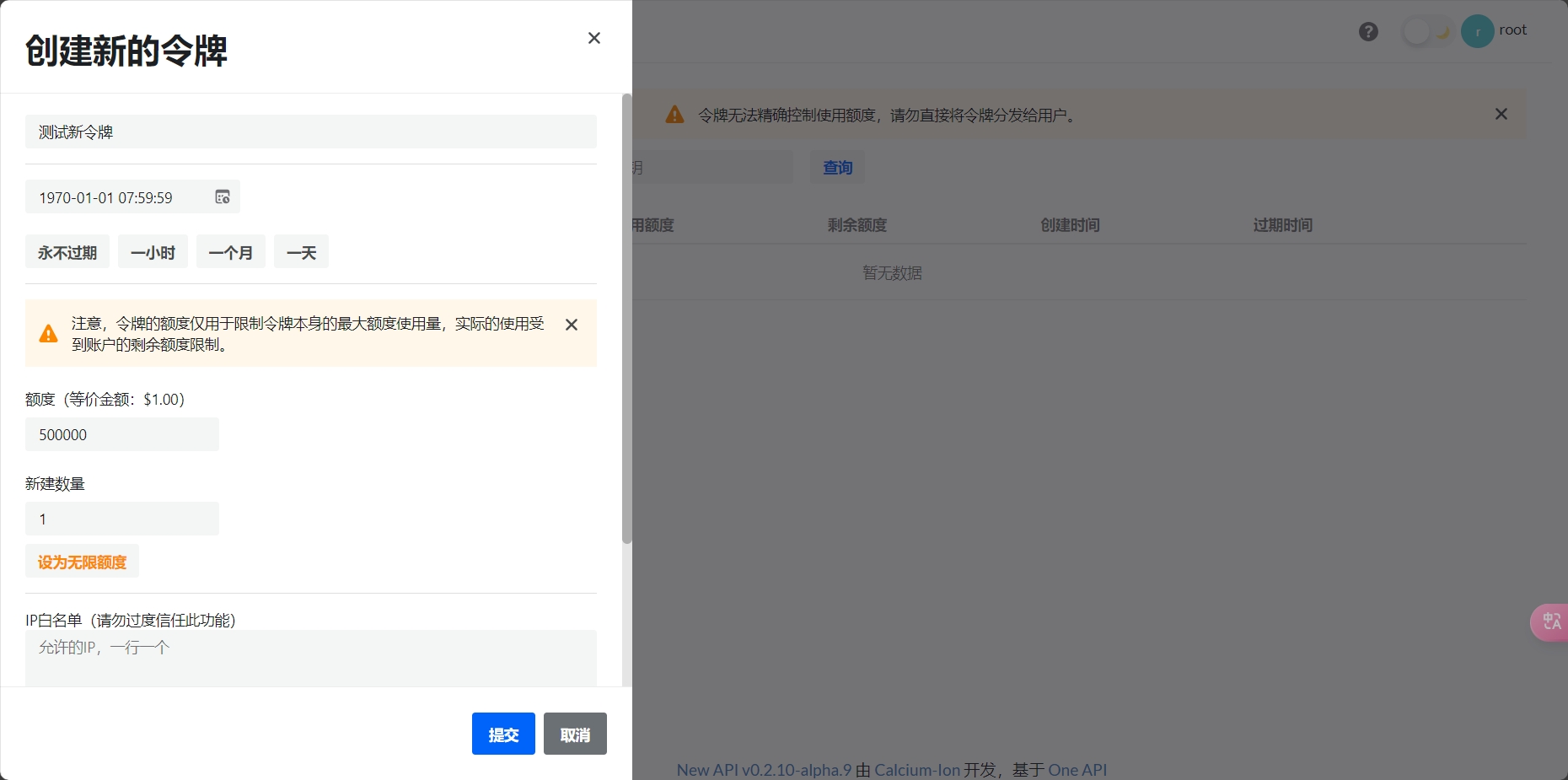
2.访问令牌(示例令牌):
api_key="sk-AlM69uPA53Xq7rjJtgR3z5q04vgDyZftVa0FsN5T0IwFC8yd"
具体使用示例:
from openai import OpenAI
client = OpenAI(api_key="sk-AlM69uPA53Xq7rjJtgR3z5q04vgDyZftVa0FsN5T0IwFC8yd", base_url="https://samlax12-newapi.hf.space/ai/v1")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)

当我们部署好NewAPI后,就可以使用OpenAI的API格式来统一调用多个大模型了。这里有一个非常实用的功能叫"模型重定向",让我来解释一下它是如何工作的。
在NewAPI的后台设置中,我们可以设置模型映射关系:
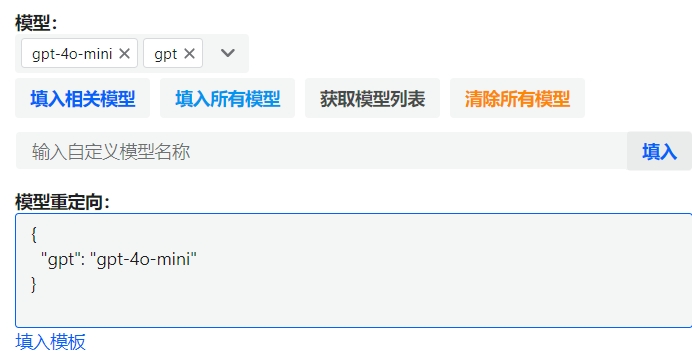
{
"gpt": "gpt-4o-mini"
}
这个设置的含义是:当你在代码中请求"gpt"这个模型时,系统会自动帮你调用"gpt-4o-mini"。这就像是给模型起了一个更简单的别名。为什么要这样做呢?
主要有两个原因: 1. 简化代码:你可以用一个简短的名称来代替较长的模型名 2. 灵活切换:如果以后想换用其他模型,只需要在后台改一下映射关系,而不用修改代码 下面是一个具体的使用示例:
from openai import OpenAI
client = OpenAI(
api_key="sk-AlM69uPA53Xq7rjJtgR3z5q04vgDyZftVa0FsN5T0IwFC8yd",
base_url="https://samlax12-newapi.hf.space/ai/v1"
)
response = client.chat.completions.create(
model="gpt", # 这里使用的是我们映射的简短名称
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
重要提示:别忘了在NewAPI的模型管理页面中添加你映射后的模型名称(在这个例子中就是"gpt")。如果不添加,系统会认为这个模型不存在,导致调用失败。