在这个AI快速发展的时代,你是否也想让AI更好地理解和运用你的专业知识?是否希望搭建一个既能准确回答问题,又能保护数据隐私的AI助手?今天,让我们一起探索如何打造一个基于RAG技术的本地知识库聊天助手。
什么是RAG?为什么我们需要它?
想象一下,你正在和一位博学的助手对话。这位助手不仅拥有强大的对话能力,更重要的是,他能实时查阅你提供的专业文档和资料,给出准确的、有依据的回答。这就是RAG(检索增强生成)技术带来的魔力。
简单来说,RAG就像给AI配备了一个"智能笔记本":当你问问题时,它会先在你提供的文档中搜索相关信息,然后基于这些找到的信息,结合自身的语言能力,生成准确而自然的回答。
随着大语言模型(LLM)的发展,我们确实获得了一个能力强大的对话助手。但在实际应用中,我们发现它们往往会产生"幻觉"——看似流畅自然但实际并不准确的回答。这并不奇怪,因为这些模型的知识来自训练数据,不仅可能已经过时,而且无法包含你的专业领域知识。
RAG技术提供了一个优雅的解决方案:它让AI在回答问题时能够实时查阅你提供的文档资料。这就像一个专业助手,在回答问题时会先翻阅相关的参考资料,确保回答既准确又有依据。这不仅大大降低了AI的"幻觉"问题,还让AI能够基于最新、最相关的信息来回答问题。
为什么需要本地知识库?
在实际工作中,我们经常需要处理一些内部文档、技术资料或者私密信息。直接使用在线AI服务意味着要将这些敏感数据上传到第三方服务器,这显然存在安全隐患。而搭建本地知识库就像给AI配备了一个私人图书馆,它只会查阅和使用你授权的文档,既确保了数据安全,又保证了回答的准确性。
通过本地知识库,你的AI助手可以:
1.准确回答关于公司产品、政策或技术文档的问题
2.确保敏感信息不会泄露到外部
3.始终基于最新的内部资料提供答案
4.降低使用成本,避免频繁的API调用费用
我们将会学到什么?
在这个教程中,我会带你一步步实现这个AI知识库助手。我们会经历两个主要阶段:
第一阶段:从最基础的控制台应用开始,帮助你理解RAG的核心工作原理:
如何处理和存储文档?
如何实现向量检索?
如何生成基于本地知识库的“准确”回答?
第二阶段:升级到一个完整的Web应用,使用Python + Flask + HTML构建界面友好的AI聊天助手
我们会用最简单的方式,一步步完成这个项目。每一步我都会尽量详细解释代码的作用。
先来理解一下本地知识库问答助手的工作原理
知识库是如何工作的?
想象一下我们在阅读一本书时的场景:当我们希望回忆这本书的某个情节时,我们会先找到相关的章节,然后再找到相关的段落,最后再基于这些内容来进行总结。本地知识库问答助手也是采用类似的方式工作。
比如当用户询问"项目A的具体预算是多少?"时,系统会经历以下步骤:
第一步:将问题转化为向量形式。就像是在给这个问题制作一个特殊的"标签",这个"标签"能够帮助我们找到最相关的内容。
第二步:在知识库中检索相似内容。系统会将问题的"标签"与之前存储的所有文档片段进行比较,找出最相关的部分。这就像是在书中使用目录或索引快速找到相关章节。
第三步:结合检索到的内容生成答案。系统不是简单地复制找到的内容,而是会理解这些信息,然后生成一个完整、准确的答案。这就像是一个专业的助手,先阅读相关资料,再用自己的话回答你的问题。
为什么需要向量化存储?
传统的关键词搜索往往难以理解问题的真正含义。例如,当用户问"公司的年度发展计划是什么?"时,相关文档中可能并没有出现"年度发展计划"这个确切的词组,但可能会包含"战略规划"、"年度目标"等相关表述。
通过将文本转换为向量,系统能够理解词语之间的语义关联,从而找到真正相关的信息。这就像是在比较两段文本的"意思"而不是简单的"字面内容"。
实际的检索流程示例
系统会进行如下处理:
1. 文档预处理:首先将产品文档分割成合适的片段,每个片段大约500-1000字符。这样可以确保检索的精确性,同时保持足够的上下文信息。
2. 向量存储:对每个文档片段生成向量表示,并存储在本地数据库中。同时保存原始文本和其对应的向量索引。
3. 相似度检索:当收到用户问题时,系统会:
计算问题的向量表示
在向量数据库中找出最相似的几个片段
将这些相关内容作为上下文提供给大语言模型
4. 答案生成:系统会告诉大语言模型:“提示词+检索到的相关内容+用户问题”,确保生成的答案严格基于检索到的文档内容,当然必要的时候也需要附带历史记录
通过这种方式,系统能够在保证回答准确性的同时,有效降低API调用成本,并确保信息安全性。
理解RAG聊天助手的核心逻辑
上面那堆东西看起来还是太复杂了,让我们通过一个具体的业务场景,来深入理解一个最简单的基于RAG的本地知识库问答系统是如何工作的。
一个典型的业务场景
想象你是一家企业的客服主管,每天都要处理大量关于产品、政策和流程的咨询。你有一份详细的产品手册,但在数百页的文档中快速找到准确的信息并不容易。这正是RAG系统能够帮助的地方。
文档处理的实际流程
假设你有一份产品手册文档:
【产品退换货政策】
第一章:退货规则
1.1 所有产品支持7天无理由退货
1.2 退货时需要提供完整的包装和随附配件
1.3 部分定制化产品除外(详见附录A)
第二章:退货流程
2.1 在线提交退货申请
2.2 等待客服审核确认
2.3 按照指定物流进行退回
...
RAG系统会将这份文档处理成多个独立但有关联的知识片段:
片段1:所有产品支持7天无理由退货,退货时需要提供完整的包装和随附配件。部分定制化产品除外。
片段2:退货流程包括:1.在线提交退货申请 2.等待客服审核确认 3.按照指定物流进行退回。
...
问答过程的完整示例
当用户提出问题时,系统的工作流程是这样的:
1. 用户提问:
"请问你们的退货政策是怎么规定的?需要满足什么条件?"
2. RAG系统检索相关文档片段:
相关度:0.95 - "所有产品支持7天无理由退货,退货时需要提供完整的包装和随附配件。部分定制化产品除外。"
相关度:0.82 - "退货流程包括:1.在线提交退货申请 2.等待客服审核确认 3.按照指定物流进行退回。"
3. 系统构建完整的上下文提示:
你是一个专业的客服助手。请基于以下参考资料,准确回答用户的问题。请只使用参考资料中提供的信息,如果信息不足,请明确告知。
参考资料:
1. 所有产品支持7天无理由退货,退货时需要提供完整的包装和随附配件。部分定制化产品除外。
2. 退货流程包括:1.在线提交退货申请 2.等待客服审核确认 3.按照指定物流进行退回。
用户问题:请问你们的退货政策是怎么规定的?需要满足什么条件?
4. 系统基于特殊提问生成特定回答:
根据我们的政策,我们提供7天无理由退货服务,但需要满足以下条件:
1. 在购买后7天内提出退货申请
2. 商品包装和配件需要保持完整
3. 注意:定制化产品可能不适用此政策
退货具体流程是:
1. 在我们的系统中提交退货申请
2. 等待客服团队审核确认
3. 使用指定的物流渠道退回商品
我们之前实现的多轮对话中的上下文理解也可以复用
RAG系统处理后续的追问:
用户追问:
"定制化产品具体指哪些?"
系统新检索的文档片段:
相关度:0.88 - "附录A:定制化产品包括:1.定制尺寸的家具 2.刻字服务的饰品 3.私人订制的电子产品。这些产品一经生产,除质量问题外不支持退换。"
系统回答:
根据文档说明,定制化产品包括:
1. 定制尺寸的家具
2. 经过刻字服务的饰品
3. 私人订制的电子产品
这些定制产品由于其特殊性,除非存在质量问题,否则不支持退换。
通过这个完整的示例,我们可以看到RAG系统的几个关键优势:
1. 精确的信息定位:能够从大量文档中准确找到与问题最相关的内容
2. 可靠的答案生成:回答严格基于文档内容,避免产生虚假信息
3. 专业的对话能力:既保持了AI流畅的表达,又确保了信息的准确性
4. 灵活的上下文理解:能够处理用户的追问,保持对话的连贯性
技术选型与实现细节
向量模型选择:M3E-Large
在构建本地知识库问答系统时,向量模型的选择至关重要。我们选择了 MokaAI 开源的 M3E-Large 模型作为文本向量化的核心组件。这个选择基于以下几个关键考虑:
优势与特点
1. 中英双语支持:M3E-Large 经过2200万+中文句对数据的训练,能够同时处理中英文本,满足多语言场景需求。
2. 轻量级部署:作为一个小型模型,M3E-Large 可以在CPU环境下运行,降低了硬件要求,使私有化部署更加灵活。
3. 开源可控:模型完全开源,可以根据具体需求进行微调和优化。
4. 性能表现:在文本相似度计算和检索任务中表现出色,与商业模型(如OpenAI的text-embedding系列模型)相比具有竞争力。
当然我们也可以直接使用OpenAI的文本嵌入模型比如:text-embedding-ada-002,反正请求逻辑一模一样,改一下key和url就行
向量数据库的存储设计
我们这里采用了混合存储策略,结合SQLite关系数据库和文件系统,实现高效的向量检索和文本存储。
数据库设计
系统使用三个主要表格组织数据:
1. chunks表:存储文档分块信息
CREATE TABLE chunks (
id TEXT PRIMARY KEY,
filename TEXT,
chunk_text TEXT,
chunk_index INTEGER,
created_at TIMESTAMP,
vector_ids TEXT
)
2. vector_mappings表:管理向量ID与文本块的映射关系
CREATE TABLE vector_mappings (
vector_id INTEGER PRIMARY KEY AUTOINCREMENT,
chunk_id TEXT,
embedding_type TEXT,
FOREIGN KEY (chunk_id) REFERENCES chunks(id)
)
3. processed_files表:追踪文件处理状态
CREATE TABLE processed_files (
filename TEXT PRIMARY KEY,
file_hash TEXT,
processed_at TIMESTAMP,
file_size INTEGER,
chunk_count INTEGER
)
向量存储优化
为了提高检索效率,我们采用了以下策略:
1. 向量文件存储:使用NumPy的二进制格式(.npy)存储向量数据,实现快速加载和检索。
2. 近邻索引:使用sklearn的NearestNeighbors实现向量检索,采用余弦相似度度量。
3. 增量更新:支持文档的增量处理,避免重复计算已处理文档的向量。
文档处理流程
让我们通过一个具体的pdf/word文档处理示例,来理解整个系统的工作流程:
文档预处理
1. 文件验证:
def calculate_file_hash(self, file_path: str) -> str:
"""计算文件的MD5哈希值"""
hash_md5 = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
2. 文本提取:
def read_pdf(self, pdf_path: str) -> str:
try:
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
return text
except Exception as e:
raise ValueError(f"PDF读取失败: {str(e)}")
def read_word(self, doc_path: str) -> str:
try:
doc = Document(doc_path)
text = []
for paragraph in doc.paragraphs:
text.append(paragraph.text)
return '\n'.join(text)
except Exception as e:
raise ValueError(f"Word文档读取失败: {str(e)}")
分块策略
我们采用了智能的文本分块策略,确保每个块都具有完整的语义:
def split_text(self, text: str) -> List[str]:
try:
chunks = []
start = 0
text_length = len(text)
while start < text_length:
end = min(start + self.chunk_size, text_length)
if end < text_length:
split_point = text.rfind('.', start, end)
if split_point == -1:
for punct in ['. ', '? ', '! ', '\n', '. ', ', ', ' ']:
split_point = text.rfind(punct, start, end)
if split_point != -1:
break
if split_point == -1:
split_point = end
chunks.append(text[start:split_point + 1].strip())
start = split_point + 1
else:
chunks.append(text[start:end].strip())
break
return [chunk for chunk in chunks if chunk]
except MemoryError:
raise ValueError("文件太大,无法处理。请尝试拆分文件后重试。")
except Exception as e:
raise ValueError(f"分割文本时出错: {str(e)}")
向量化与索引
文本块生成后,通过M3E-Large模型进行向量化:
1. 向量生成:调用本地部署的向量服务
2. 索引更新:将新向量添加到现有索引
3. 数据持久化:同步更新数据库和向量文件
同时m3e模型的官方MokaAI开源了基本的使用逻辑:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
M3E 系列的所有模型在设计的时候就考虑到完全兼容 sentence-transformers ,所以我们可以通过替换名称字符串的方式在所有支持 sentence-transformers 的项目中无缝使用 M3E Models,比如 chroma, guidance, semantic-kernel 。 (当然我们暂时不需要探究这部分)
现在让我们开始实战部分的代码设计与实现
先封装一个简单的 文本嵌入模型 API 服务
我们之前提到过:OpenAI的API格式因其设计合理性和广泛采用,已成为行业事实标准,所以我们对于文本向量化的标准逻辑也是参考Openai格式的文本嵌入部分的代码:
post https://api.openai.com/v1/embeddings
Openai给出的相关的请求逻辑是:
curl https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input": "The food was delicious and the waiter...",
"model": "text-embedding-ada-002",
"encoding_format": "float"
}'
或
from openai import OpenAI
client = OpenAI(api_key="<API Key>", base_url="https://api.openai.com/v1")
client.embeddings.create(
model="text-embedding-ada-002",
input="The food was delicious and the waiter...",
encoding_format="float"
)
响应的格式是:
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
但是如果直接使用OpenAI的嵌入式服务会受到网络延迟与高成本的问题, 所以我们现在才要把将 m3e 模型封装成一个类似于 OpenAI 文本嵌入接口的格式,允许用户通过 API 调用来获取文本的嵌入向量。我们通过这个接口,可以把文本输入传递给模型,模型会返回相应的嵌入向量,格式和 OpenAI 的 text-embedding-ada-002 模型一致。
这部分的代码在底下粘贴一下,其实是无意间找到的,我自己简单调整了一下,还能用暂时就不过多改动了:
from fastapi import FastAPI, Depends, HTTPException, status
from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials
from sentence_transformers import SentenceTransformer
from pydantic import BaseModel
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
import tiktoken
import numpy as np
from scipy.interpolate import interp1d
from typing import List
from sklearn.preprocessing import PolynomialFeatures
import torch
import os
#环境变量传入
sk_key = os.environ.get('sk-key', 'sk-aaabbbcccdddeeefffggghhhiiijjjkkk')
# 创建一个FastAPI实例
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 创建一个HTTPBearer实例
security = HTTPBearer()
# 预加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 检测是否有GPU可用,如果有则使用cuda设备,否则使用cpu设备
if torch.cuda.is_available():
print('本次加载模型的设备为GPU: ', torch.cuda.get_device_name(0))
else:
print('本次加载模型的设备为CPU.')
model = SentenceTransformer('./moka-ai_m3e-large', device=device)
class EmbeddingRequest(BaseModel):
input: List[str]
model: str
class EmbeddingResponse(BaseModel):
data: list
model: str
object: str
usage: dict
def num_tokens_from_string(string: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens = len(encoding.encode(string))
return num_tokens
# 插值法
def interpolate_vector(vector, target_length):
original_indices = np.arange(len(vector))
target_indices = np.linspace(0, len(vector)-1, target_length)
f = interp1d(original_indices, vector, kind='linear')
return f(target_indices)
def expand_features(embedding, target_length):
poly = PolynomialFeatures(degree=2)
expanded_embedding = poly.fit_transform(embedding.reshape(1, -1))
expanded_embedding = expanded_embedding.flatten()
if len(expanded_embedding) > target_length:
# 如果扩展后的特征超过目标长度,可以通过截断或其他方法来减少维度
expanded_embedding = expanded_embedding[:target_length]
elif len(expanded_embedding) < target_length:
# 如果扩展后的特征少于目标长度,可以通过填充或其他方法来增加维度
expanded_embedding = np.pad(expanded_embedding, (0, target_length - len(expanded_embedding)))
return expanded_embedding
@app.post("/v1/embeddings", response_model=EmbeddingResponse)
async def get_embeddings(request: EmbeddingRequest, credentials: HTTPAuthorizationCredentials = Depends(security)):
if credentials.credentials != sk_key:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authorization code",
)
# 计算嵌入向量和tokens数量
embeddings = [model.encode(text) for text in request.input]
# 如果嵌入向量的维度不为1536,则使用插值法扩展至1536维度
# embeddings = [interpolate_vector(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings]
# 如果嵌入向量的维度不为1536,则使用特征扩展法扩展至1536维度
embeddings = [expand_features(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings]
# Min-Max normalization
# embeddings = [(embedding - np.min(embedding)) / (np.max(embedding) - np.min(embedding)) if np.max(embedding) != np.min(embedding) else embedding for embedding in embeddings]
embeddings = [embedding / np.linalg.norm(embedding) for embedding in embeddings]
# 将numpy数组转换为列表
embeddings = [embedding.tolist() for embedding in embeddings]
prompt_tokens = sum(len(text.split()) for text in request.input)
total_tokens = sum(num_tokens_from_string(text) for text in request.input)
response = {
"data": [
{
"embedding": embedding,
"index": index,
"object": "embedding"
} for index, embedding in enumerate(embeddings)
],
"model": request.model,
"object": "list",
"usage": {
"prompt_tokens": prompt_tokens,
"total_tokens": total_tokens,
}
}
return response
if __name__ == "__main__":
uvicorn.run("app:app", host='0.0.0.0', port=6006, workers=1)
具体结构如下:
文本嵌入生成:接受一个文本输入(字符串或字符串列表),使用 m3e 模型(通过 sentence-transformers 库)将其转换为一个 1536 维的嵌入向量。
API 接口:提供 /v1/embeddings 接口,格式和 OpenAI 的 API 非常类似。你可以通过 HTTP 请求向该接口发送文本数据,接口将返回与 OpenAI text-embedding-ada-002 类似的嵌入向量。
认证安全:使用 Bearer Token 验证机制,保证只有提供有效密钥的用户才能访问 API。
数据处理:在生成嵌入向量后,代码还对向量进行了归一化(使其长度为 1),确保返回的向量标准化,方便后续的相似度计算等任务。
使用方式:
请求方式:通过 HTTP POST 请求调用 /v1/embeddings 接口,传递 input(文本输入)和 model(模型名称)参数。
响应格式:响应中包含嵌入向量(一个 1536 维的浮点数数组)和模型相关信息,符合 OpenAI API 的返回格式。
启动这个服务的命令是:(当然要简单点也可以改成flask)
uvicorn embedding_service:app --host 0.0.0.0 --port 6006 --workers 1
再创建一个RAG对话聊天服务
from openai import OpenAI
import fitz
from docx import Document
import os
from typing import List, Dict
import sqlite3
from datetime import datetime
from uuid import uuid4
import numpy as np
from sklearn.neighbors import NearestNeighbors
import pickle
from tqdm import tqdm
import hashlib
class RAGChatBot:
def __init__(self):
self.chat_client = OpenAI(
api_key="sk-xxx",
base_url="https://api.openai.com/v1"
)
self.embedding_client = OpenAI(
api_key="sk-aaabbbcccdddeeefffggghhhiiijjjkkk",
base_url="http://localhost:6006/v1"
)
self.messages = []
self.chunk_size = 500
self.chunk_overlap = 100
self.vector_dim = 1536
self.index_file = "vector_store.pkl"
self.vectors_file = "vectors.npy"
self.vector_index = NearestNeighbors(n_neighbors=5, metric='cosine')
if os.path.exists(self.index_file) and os.path.exists(self.vectors_file):
with open(self.index_file, 'rb') as f:
self.vector_index = pickle.load(f)
self.stored_vectors = np.load(self.vectors_file)
self.vector_index.fit(self.stored_vectors)
else:
self.stored_vectors = np.empty((0, self.vector_dim))
self._init_database()
def _init_database(self):
conn = sqlite3.connect("knowledge_base.db")
cursor = conn.cursor()
# 存储文档块和元数据的表
cursor.execute('''
CREATE TABLE IF NOT EXISTS chunks (
id TEXT PRIMARY KEY,
filename TEXT,
chunk_text TEXT,
chunk_index INTEGER,
created_at TIMESTAMP,
vector_ids TEXT
)
''')
# 块ID和向量ID之间的映射表
cursor.execute('''
CREATE TABLE IF NOT EXISTS vector_mappings (
vector_id INTEGER PRIMARY KEY AUTOINCREMENT,
chunk_id TEXT,
embedding_type TEXT,
FOREIGN KEY (chunk_id) REFERENCES chunks(id)
)
''')
# 新增:已处理文件记录表
cursor.execute('''
CREATE TABLE IF NOT EXISTS processed_files (
filename TEXT PRIMARY KEY,
file_hash TEXT,
processed_at TIMESTAMP,
file_size INTEGER,
chunk_count INTEGER
)
''')
conn.commit()
conn.close()
def calculate_file_hash(self, file_path: str) -> str:
"""计算文件的MD5哈希值"""
hash_md5 = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
def is_file_processed(self, file_path: str) -> bool:
"""检查文件是否已经处理过"""
filename = os.path.basename(file_path)
file_hash = self.calculate_file_hash(file_path)
file_size = os.path.getsize(file_path)
conn = sqlite3.connect("knowledge_base.db")
cursor = conn.cursor()
cursor.execute('''
SELECT file_hash, file_size FROM processed_files
WHERE filename = ?
''', (filename,))
result = cursor.fetchone()
conn.close()
if result:
stored_hash, stored_size = result
return stored_hash == file_hash and stored_size == file_size
return False
def mark_file_processed(self, file_path: str, chunk_count: int):
"""将文件标记为已处理"""
filename = os.path.basename(file_path)
file_hash = self.calculate_file_hash(file_path)
file_size = os.path.getsize(file_path)
conn = sqlite3.connect("knowledge_base.db")
cursor = conn.cursor()
cursor.execute('''
INSERT OR REPLACE INTO processed_files
(filename, file_hash, processed_at, file_size, chunk_count)
VALUES (?, ?, ?, ?, ?)
''', (filename, file_hash, datetime.now(), file_size, chunk_count))
conn.commit()
conn.close()
def read_pdf(self, pdf_path: str) -> str:
try:
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
return text
except Exception as e:
raise ValueError(f"PDF读取失败: {str(e)}")
def read_word(self, doc_path: str) -> str:
try:
doc = Document(doc_path)
text = []
for paragraph in doc.paragraphs:
text.append(paragraph.text)
return '\n'.join(text)
except Exception as e:
raise ValueError(f"Word文档读取失败: {str(e)}")
def process_document(self, file_path: str) -> str:
try:
if file_path.lower().endswith('.pdf'):
return self.read_pdf(file_path)
elif file_path.lower().endswith(('.docx', '.doc')):
return self.read_word(file_path)
else:
raise ValueError("不支持的文件格式。仅支持PDF和Word文档。")
except Exception as e:
raise ValueError(f"处理文件失败: {str(e)}")
def split_text(self, text: str) -> List[str]:
try:
chunks = []
start = 0
text_length = len(text)
while start < text_length:
end = min(start + self.chunk_size, text_length)
if end < text_length:
split_point = text.rfind('.', start, end)
if split_point == -1:
for punct in ['. ', '? ', '! ', '\n', '. ', ', ', ' ']:
split_point = text.rfind(punct, start, end)
if split_point != -1:
break
if split_point == -1:
split_point = end
chunks.append(text[start:split_point + 1].strip())
start = split_point + 1
else:
chunks.append(text[start:end].strip())
break
return [chunk for chunk in chunks if chunk]
except MemoryError:
raise ValueError("文件太大,无法处理。请尝试拆分文件后重试。")
except Exception as e:
raise ValueError(f"分割文本时出错: {str(e)}")
def get_embeddings(self, texts: List[str]) -> List[List[float]]:
try:
response = self.embedding_client.embeddings.create(
model="m3e-large",
input=texts
)
return [item.embedding for item in response.data]
except Exception as e:
raise ValueError(f"获取向量嵌入失败: {str(e)}")
def index_document(self, file_path: str):
filename = os.path.basename(file_path)
# 检查文件是否已处理
if self.is_file_processed(file_path):
print(f"\n文件 {filename} 已经处理过,跳过处理...")
return
try:
text = self.process_document(file_path)
print(f"\n处理文件: {filename}")
chunks = self.split_text(text)
print(f"文件已分割为 {len(chunks)} 个文本块")
if not chunks:
raise ValueError("未能提取到有效文本内容")
conn = sqlite3.connect("knowledge_base.db")
cursor = conn.cursor()
all_new_embeddings = []
for chunk_idx, chunk in enumerate(tqdm(chunks, desc="生成向量嵌入", unit="块")):
try:
embeddings = self.get_embeddings([chunk])[0]
all_new_embeddings.append(embeddings)
chunk_id = str(uuid4())
vector_id = len(self.stored_vectors) + len(all_new_embeddings) - 1
cursor.execute('''
INSERT INTO chunks (id, filename, chunk_text, chunk_index, created_at, vector_ids)
VALUES (?, ?, ?, ?, ?, ?)
''', (chunk_id, filename, chunk, chunk_idx, datetime.now(), str([vector_id])))
cursor.execute('''
INSERT INTO vector_mappings (vector_id, chunk_id, embedding_type)
VALUES (?, ?, ?)
''', (vector_id, chunk_id, 'default'))
if chunk_idx % 10 == 0:
conn.commit()
except Exception as e:
print(f"\n处理第 {chunk_idx + 1} 个文本块时出错: {str(e)}")
continue
if all_new_embeddings:
new_embeddings = np.array(all_new_embeddings)
self.stored_vectors = np.vstack([self.stored_vectors, new_embeddings])
self.vector_index.fit(self.stored_vectors)
with open(self.index_file, 'wb') as f:
pickle.dump(self.vector_index, f)
np.save(self.vectors_file, self.stored_vectors)
conn.commit()
conn.close()
# 标记文件为已处理
self.mark_file_processed(file_path, len(chunks))
print(f"\n成功完成文件索引: {filename}")
print(f"- 总计处理文本块: {len(chunks)} 个")
print(f"- 向量维度: {self.vector_dim}")
print(f"- 数据库记录已更新")
print("-" * 50)
except Exception as e:
print(f"\n处理文件失败: {filename}")
print(f"错误信息: {str(e)}")
print("请检查文件格式是否正确,以及文件是否可以正常打开。")
print("-" * 50)
def retrieve_context(self, query: str) -> str:
query_embedding = self.get_embeddings([query])[0]
distances, indices = self.vector_index.kneighbors(
[query_embedding],
n_neighbors=min(5, len(self.stored_vectors))
)
similarities = 1 - distances[0]
conn = sqlite3.connect("knowledge_base.db")
cursor = conn.cursor()
chunk_scores: Dict[str, float] = {}
for vector_id, similarity in zip(indices[0], similarities):
cursor.execute('SELECT chunk_id FROM vector_mappings WHERE vector_id = ?', (int(vector_id),))
result = cursor.fetchone()
if result:
chunk_id = result[0]
if chunk_id not in chunk_scores or similarity > chunk_scores[chunk_id]:
chunk_scores[chunk_id] = similarity
contexts = []
for chunk_id, score in sorted(chunk_scores.items(), key=lambda x: x[1], reverse=True):
cursor.execute('SELECT filename, chunk_text FROM chunks WHERE id = ?', (chunk_id,))
result = cursor.fetchone()
if result:
filename, chunk_text = result
contexts.append(f"来自文件 {filename} (相关度: {score:.2f}):\n{chunk_text}")
conn.close()
return "\n\n".join(contexts)
def chat(self, user_input: str):
context = self.retrieve_context(user_input)
system_prompt = f"""你是一个知识库问答助手。请基于以下参考文档回答用户的问题。
如果无法在参考文档中找到答案,请明确告知。回答时请注明信息来源。
参考文档:
{context}"""
if not self.messages:
self.messages.append({"role": "system", "content": system_prompt})
self.messages.append({"role": "user", "content": user_input})
completion = self.chat_client.chat.completions.create(
model="gpt-4o-mini",
messages=self.messages,
stream=True
)
full_response = ""
for chunk in completion:
content = chunk.choices[0].delta.content
if content:
full_response += content
print(content, end='', flush=True)
self.messages.append({"role": "assistant", "content": full_response})
print("\n")
def main():
chatbot = RAGChatBot()
docs_directory = "docs"
if not os.path.exists(docs_directory):
os.makedirs(docs_directory)
print(f"已创建文档目录: {docs_directory}")
doc_count = 0
for filename in os.listdir(docs_directory):
if filename.lower().endswith(('.pdf', '.docx', '.doc')):
file_path = os.path.join(docs_directory, filename)
print(f"正在检查文件 {filename}...")
chatbot.index_document(file_path)
doc_count += 1
if doc_count == 0:
print(f"\n警告:在 {docs_directory} 目录中没有找到任何PDF或Word文档。")
print("请将文档放入该目录后重新运行程序。")
return
print("\n欢迎使用知识库问答助手!")
print("您可以询问任何关于已上传文档的问题。")
print("输入 'quit' 退出对话。")
while True:
user_input = input("\n您: ")
if user_input.lower() == 'quit':
print("感谢使用知识库问答助手,再见!")
break
chatbot.chat(user_input)
if __name__ == "__main__":
main()
RAGChatBot 实现说明
实现一个可靠的本地知识库问答系统,关键在于处理好文档管理、向量检索和对话生成这三个核心环节。让我们详细解析 RAGChatBot 类的设计思路和核心实现。
系统初始化与配置
RAGChatBot 在初始化时建立了两个关键的客户端连接:
def __init__(self):
self.chat_client = OpenAI(
api_key="sk-xxx",
base_url="https://api.openai.com/v1"
)
self.embedding_client = OpenAI(
api_key="sk-yyy",
base_url="http://localhost:6006/v1"
)
chat_client负责与大语言模型通信,处理对话生成任务。而 embedding_client则连接到我们之前搭建的本地文本向量化服务,用于文档和问题的向量表示。
系统采用了混合存储策略,通过SQLite数据库存储文档块和向量映射信息,同时使用文件系统存储向量数据。这种设计既保证了检索效率,又便于管理和扩展:
def _init_database(self):
# chunks表:存储文档块和元数据
cursor.execute('''
CREATE TABLE IF NOT EXISTS chunks (
id TEXT PRIMARY KEY,
filename TEXT,
chunk_text TEXT,
chunk_index INTEGER,
created_at TIMESTAMP,
vector_ids TEXT
)
''')
# vector_mappings表:管理向量ID与文本块的映射关系
cursor.execute('''
CREATE TABLE IF NOT EXISTS vector_mappings (
vector_id INTEGER PRIMARY KEY AUTOINCREMENT,
chunk_id TEXT,
embedding_type TEXT,
FOREIGN KEY (chunk_id) REFERENCES chunks(id)
)
''')
文档处理与向量索引
文档处理采用了智能分块策略,通过 chunk_size 和 chunk_overlap 参数控制分块大小和重叠程度,确保语义完整性:
self.chunk_size = 500 # 默认分块大小
self.chunk_overlap = 100 # 分块重叠长度
self.vector_dim = 1536 # 向量维度
index_document 方法实现了文档索引的完整流程:
1. 文件查重:通过计算文件哈希值避免重复处理
2. 文本提取:支持 PDF 和 Word 格式的文档读取
3. 智能分块:确保每个文本块的语义完整性
4. 向量生成:调用本地向量服务生成文本嵌入
5. 数据存储:同步更新数据库和向量存储
检索与对话生成
retrieve_context 方法使用余弦相似度进行向量检索,找出与用户问题最相关的文档片段:
def retrieve_context(self, query: str) -> str:
query_embedding = self.get_embeddings([query])[0]
distances, indices = self.vector_index.kneighbors(
[query_embedding],
n_neighbors=min(5, len(self.stored_vectors))
)
chat 方法将检索到的上下文与用户问题相结合,构建合适的提示词,指导大语言模型生成准确的回答:
def chat(self, user_input: str):
context = self.retrieve_context(user_input)
system_prompt = f"""你是一个知识库问答助手。
请基于以下参考文档回答用户的问题。
如果无法在参考文档中找到答案,请明确告知。
回答时请注明信息来源。
参考文档:
{context}"""
错误处理与优化
系统实现了完善的错误处理机制,确保在文件读取、向量生成等环节出现异常时能够优雅降级:
try:
embeddings = self.get_embeddings([chunk])[0]
except Exception as e:
print(f"\n处理第 {chunk_idx + 1} 个文本块时出错: {str(e)}")
continue
同时,通过批量提交和定期保存等策略优化了数据处理性能:
if chunk_idx % 10 == 0:
conn.commit()
通过这种模块化和健壮的设计,我们的 RAGChatBot 能够高效处理文档,准确回答问题,同时保证了系统的可靠性和可扩展性。无论是处理简单的产品咨询,还是复杂的技术问答,都能提供准确且有依据的回答。
运行效果: 先启动一下文本嵌入服务器:
首次会主动读取docs与pdfs文件夹内的word文件与pdf文件,进行知识库预处理
这个步骤只会在对文档第一次读取时才会进行处理,以后再次启动时则会检测是否已经处理防止重复操作(不过这里可以有很多种办法,我只是使用了其中之一,数据库也是,其实还有很多数据库与向量库都可以搭配选择,我这里只是为了示范方便用了sqlite与sklearn,因为这两个不需要额外添加外部数据库)。
所以二次处理相同的文档时会:
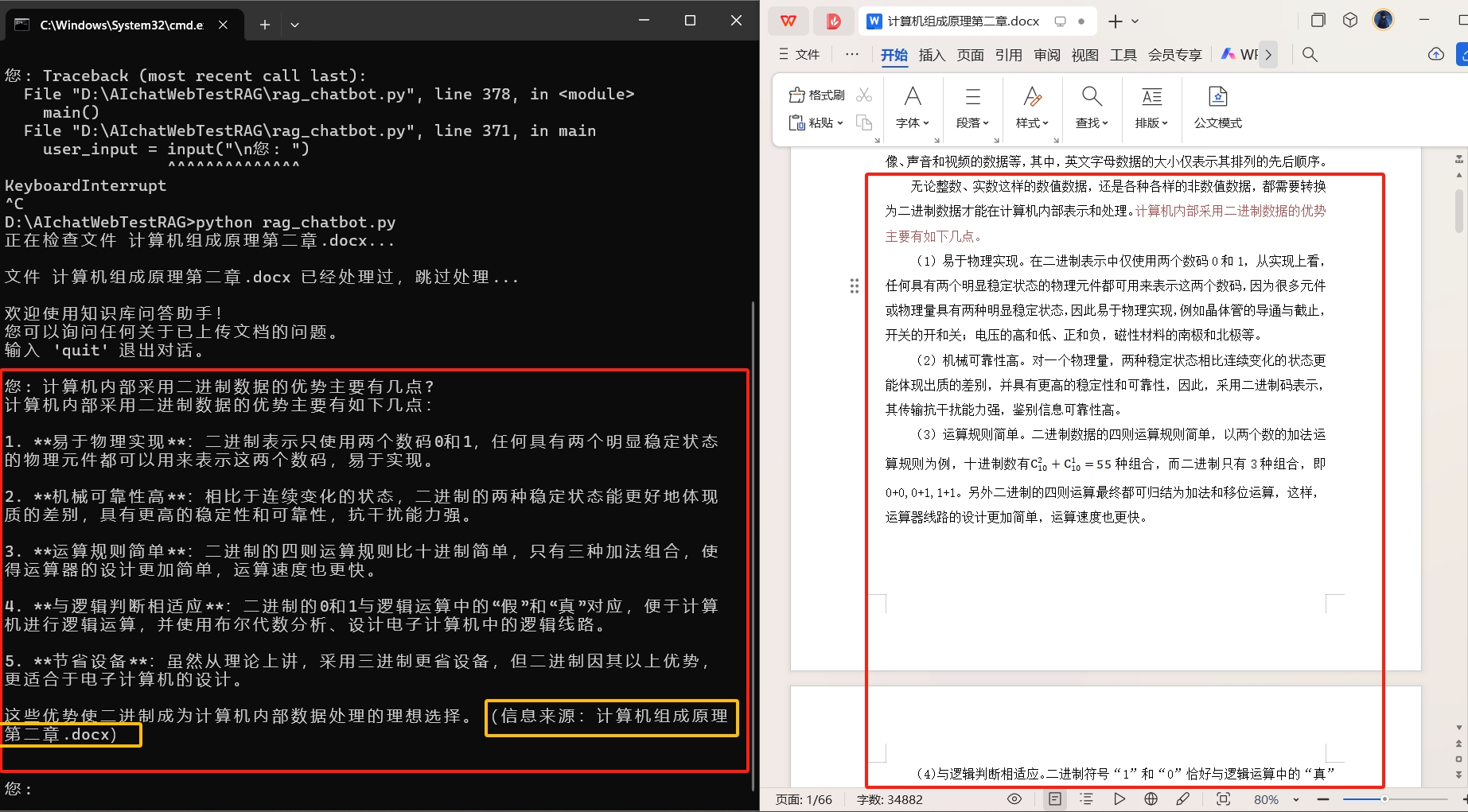

这个就是基于RAG的本地知识库聊天助手的特色,根据知识库的内容作答,让文档活起来,当然也有局限,不过我们这里暂时先忽略掉
给本地知识库聊天助手定制一件马甲
作为一名开发者,都做到这个程度了,再简单用Flask+HTML给自己的本地知识库聊天助手定制一个合理的Web UI(用户交互界面)也是应该的,毕竟谁希望天天在控制台进行对话,这风格未免太极简了点,当然都web交互了,那由前端直接上传知识库我们也可以试试了......
现在我们先晒一下最终效果:
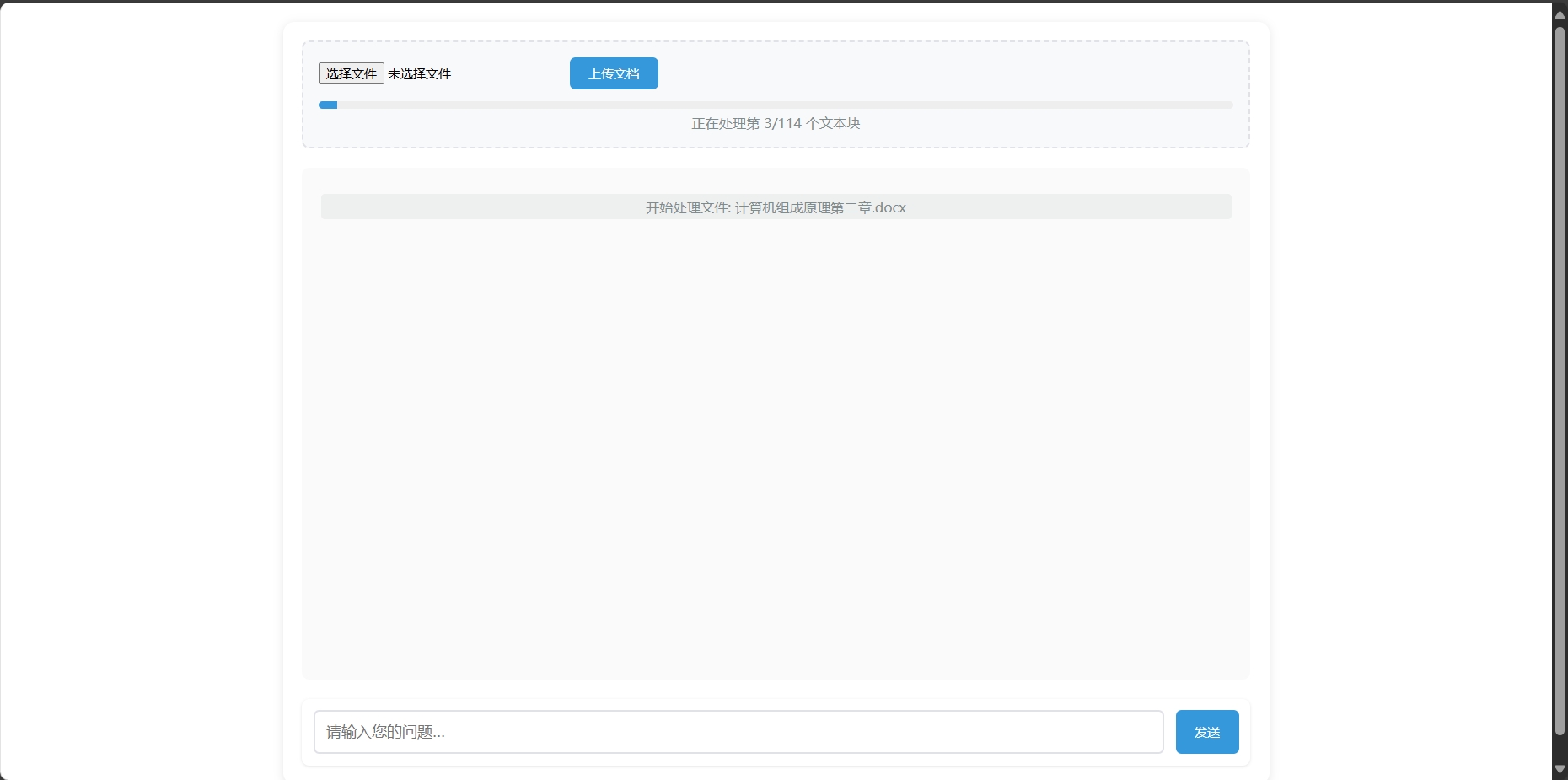
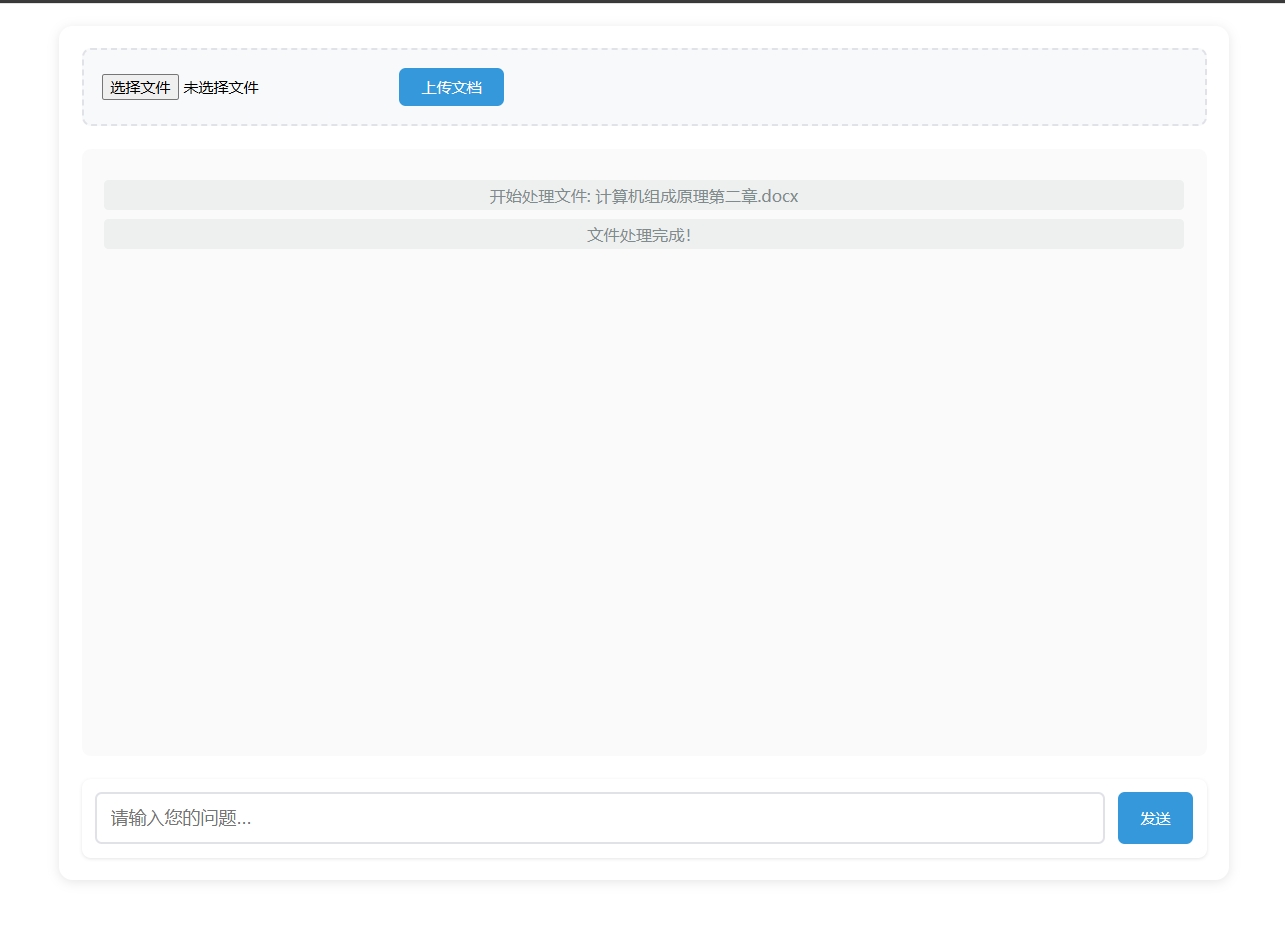
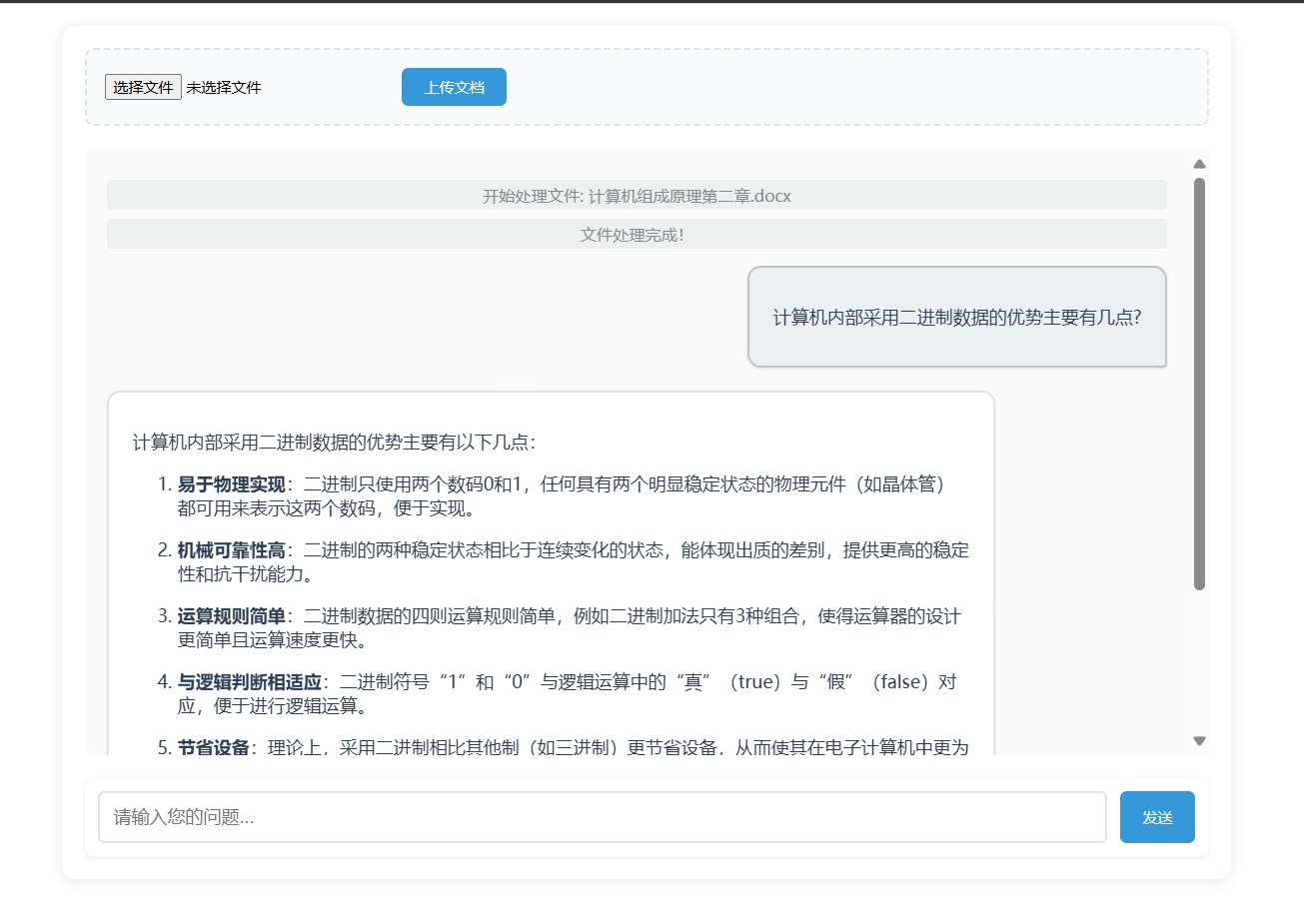
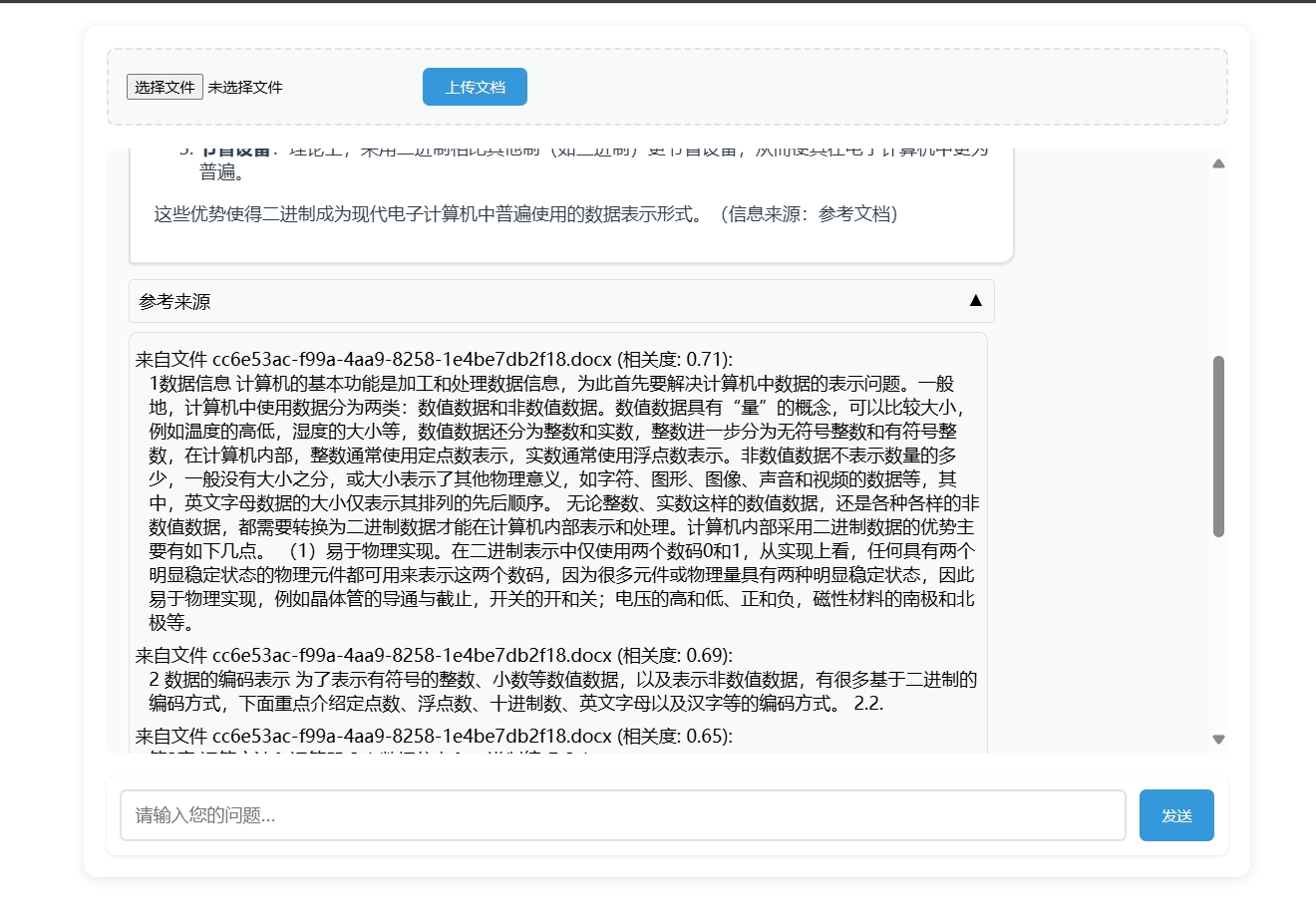
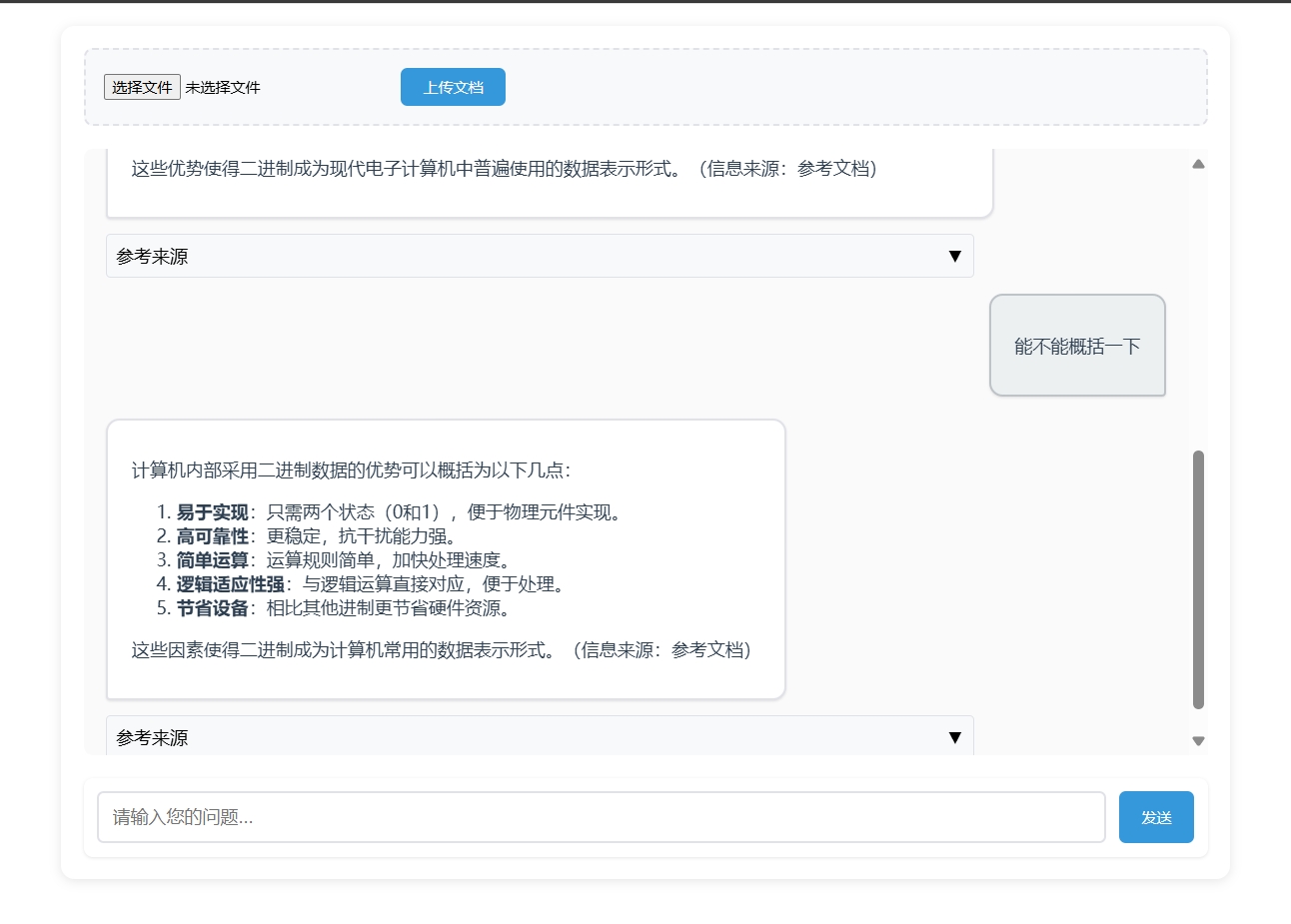
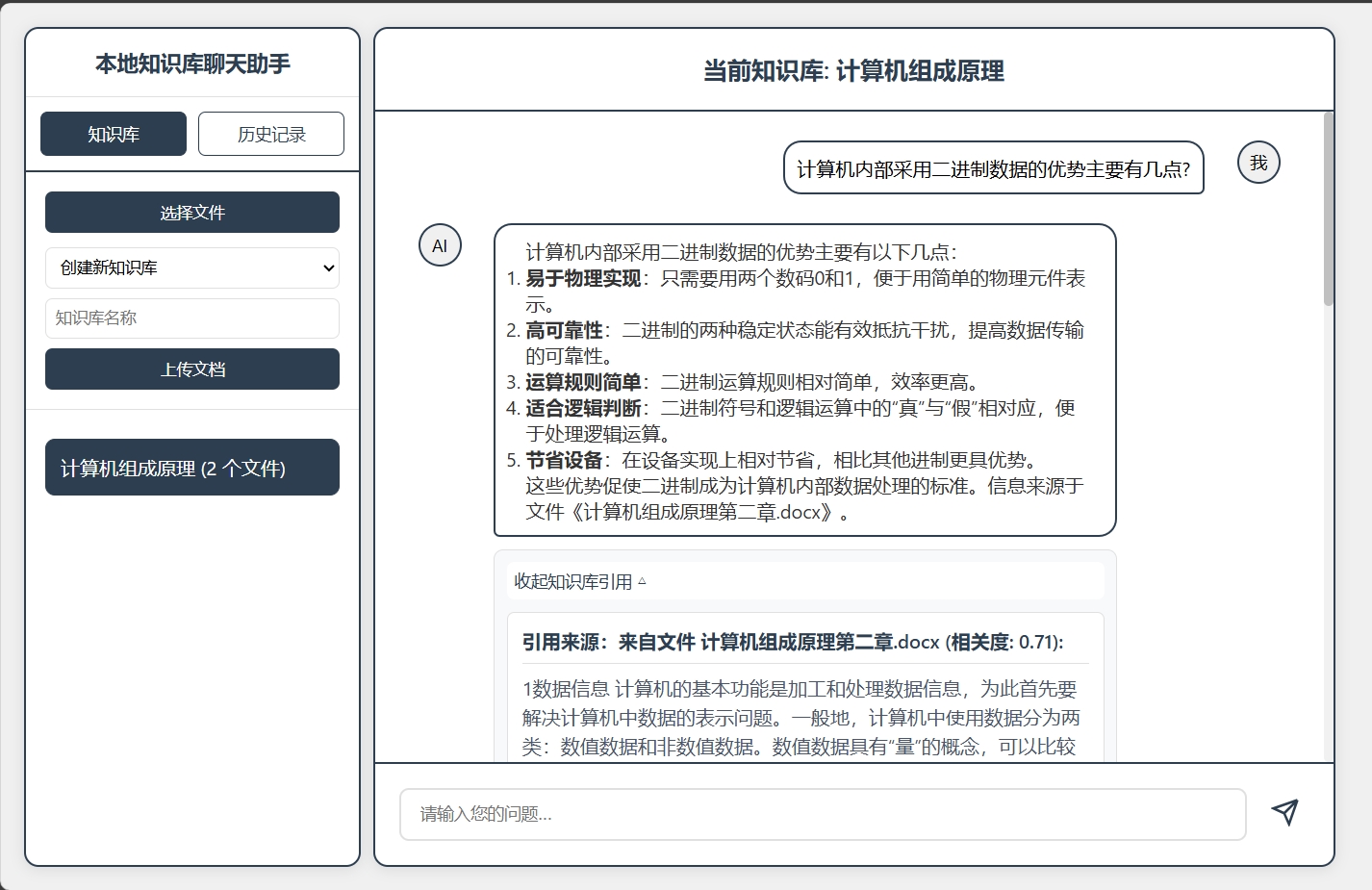
当然我们也可以再加亿点点细节(比如做成一个多知识库且一个知识库可以具备多个文档的进阶版):
具体的项目代码,不放这里占地方了,想试试的可以直接下载整合包:
技术栈还是Flask+Python+HTML
纯控制台应用整合包下载地址:
https://hf-mirror.com/datasets/samlax12/ceshi2/resolve/main/AIchatWeb-RAG.zip?download=true
带WebUI的图形化应用整合包下载地址:
https://hf-mirror.com/datasets/samlax12/ceshi2/resolve/main/AIchatWeb-RAG-WEB.zip?download=true
上面都是打包了m3e向量模型的整合包,当然我们可以直接使用Openai格式的文本嵌入服务,所以去掉了模型的轻量级的整合包在下面
控制台Lite版(<1MB)
https://hf-mirror.com/datasets/samlax12/ceshi2/resolve/main/AIchatTest-RAG-Lite.zip?download=true
WebUI Lite版(<1MB)
https://hf-mirror.com/datasets/samlax12/ceshi2/resolve/main/AIchatWeb-RAG-WEB-Lite.zip?download=true
使用Lite版只需要把: 原本的m3e-large改成text-embedding-ada-003、text-embedding-ada-002这种OpenAI格式的文本嵌入模型(向量模型),请求地址与APIkey都修改为对应的服务就行了
自己试试看吧