前言:为什么要写这篇文章
在当前国内AI领域蓬勃发展的背景下,DeepSeek-R1的开源发布无疑是一个重要的技术里程碑。这个模型最引人注目的创新在于其直接通过强化学习训练出的推理能力,摆脱了传统方法依赖大量标注数据的限制,成为目前首个开源的自带思维链的大模型。对于正在学习和研究AI的同学来说,这种新颖的训练思路无疑具有重要的启发意义。
然而,随着DeepSeek-R1的开源,市场上出现了令人忧虑的现象。一些机构和个人打着各种旗号,利用信息差进行不当牟利。从动辄收取5-10万/月的高额部署费用,到过度夸大蒸馏小模型的性能,再到打着"高门槛部署"旗号推销质量存疑的付费课程,这些行为严重违背了开源精神,也给许多对AI技术充满热情的学习者带来了困扰。
技术创新与实际表现:理性看待模型性能
在讨论部署方案之前,我们有必要先来看看DeepSeek-R1系列模型的真实性能表现。根据官方发布的评测数据,不同参数规模的模型在AIME评测上表现各异:
1.5B版本:基础准确率28.9%,多样本投票后可提升至52.7%
7B版本:基础准确率55.5%,多样本投票后可提升至83.3%
14B版本:基础准确率69.7%,多样本投票后可提升至80.0%
32B版本:基础准确率72.6%,多样本投票后可提升至83.3%
70B版本:基础准确率70.0%,多样本投票后可提升至86.7%
这些数据清晰地表明,在参数量不足的情况下,蒸馏模型与原始模型之间确实存在显著差距。这也就意味着,那些将小参数模型等同于满血的原始模型的营销说法是严重失实的。
当前部署乱象:五大主要问题
在密切关注社区动态的过程中,我观察到以下几个值得警惕的现象:
1. 过度营销: 一些机构刻意夸大蒸馏小模型的性能,误导性地宣称其能达到原始模型的水平。
2. 技术误导: 在推广纯CPU部署大模型时,往往有意忽略了性能损耗和资源占用等关键问题。虽然技术上可行,但会导致显著的性能下降和系统资源过度消耗。
3. 投机诈骗: 以部署和运营为名进行不当集资,号称需要每位会员投入5-10万/月,最终却只部署了一个32B的模型。
4. 知识误导: 在缺乏充分验证和实际测评数据的情况下,对模型性能做出片面评价。
5. 商业套利: 利用信息差推出质量存疑的付费课程和服务,而实际上DeepSeek官方始终秉持开源原则,这些内容本应人人可及。
设备安全与性能:过度勉强的危害
在讨论部署方案之前,我们还需要特别强调一个经常被忽视但极其重要的问题:过度勉强本地设备运行大型参数模型可能带来的严重后果。
许多网络教程在介绍部署方案时往往只关注“能不能跑通”,而忽视了"应不应该这样跑"的问题。强行在配置不足的设备上运行大型参数模型,可能导致以下严重问题:
首先是硬件安全隐患。长期在超负荷状态下运行会导致GPU过热,不仅会降低硬件使用寿命,严重时还可能造成永久性损坏。特别是在散热不足的笔记本设备上,这个风险更加显著。
其次是系统稳定性问题。过度占用系统资源会导致其他应用程序无法正常运行,甚至可能引发系统崩溃。在极端情况下,反复的高负载运行可能会损坏操作系统文件,导致系统需要重装。
最后是能耗与成本问题。在设备性能严重不足的情况下强行运行大模型,会导致设备持续处于高功耗状态,不仅会大幅增加电费支出,还会加速硬件老化,最终可能带来更高的设备维护和更换成本。
这也是为什么我选择介绍LMStudio作为部署方案的重要原因之一。
一个好的部署方案不仅要考虑技术可行性,更要关注设备的长期健康运行。
为什么选择LMStudio?
在这样的背景下,我决定介绍一个更加直观、门槛更低的本地部署方案——LMStudio。

选择这个工具的原因在于:
1. 它能够自动评估模型是否适合本机配置
2. 配备了用户友好的图形界面
3. 内置了问答功能,并能实时显示上下文占用
4. 无需复杂的环境配置
5. 为用户提供了可视化的模型运行环境
现在让我们开始逐步安装
先让我们到官网下载安装包:
https://lmstudio.ai/
这里粘一下Windows版本的下载直链:
https://installers.lmstudio.ai/win32/x64/0.3.9-6/LM-Studio-0.3.9-6-x64.exe
然后就是我们最熟悉的安装环节:
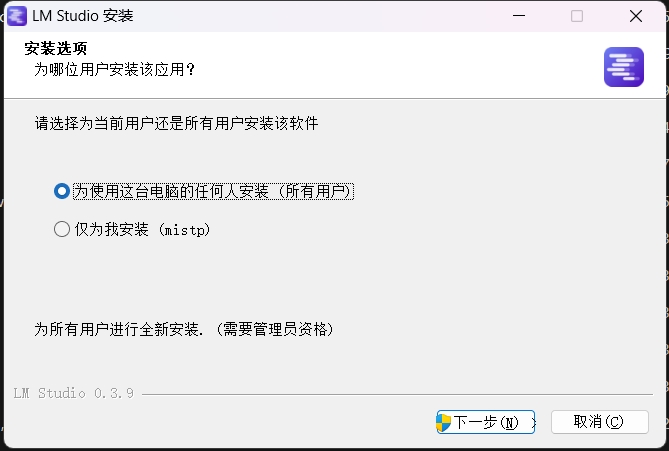
这里随便选
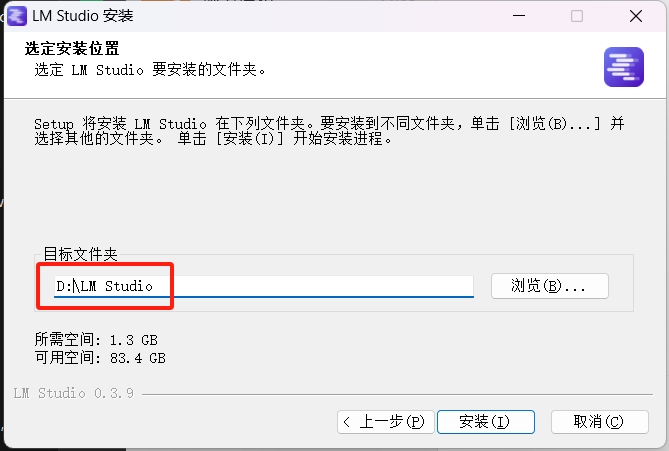
请将默认的系统盘位置修改为其他盘符
现在我们就进入到了主要界面:
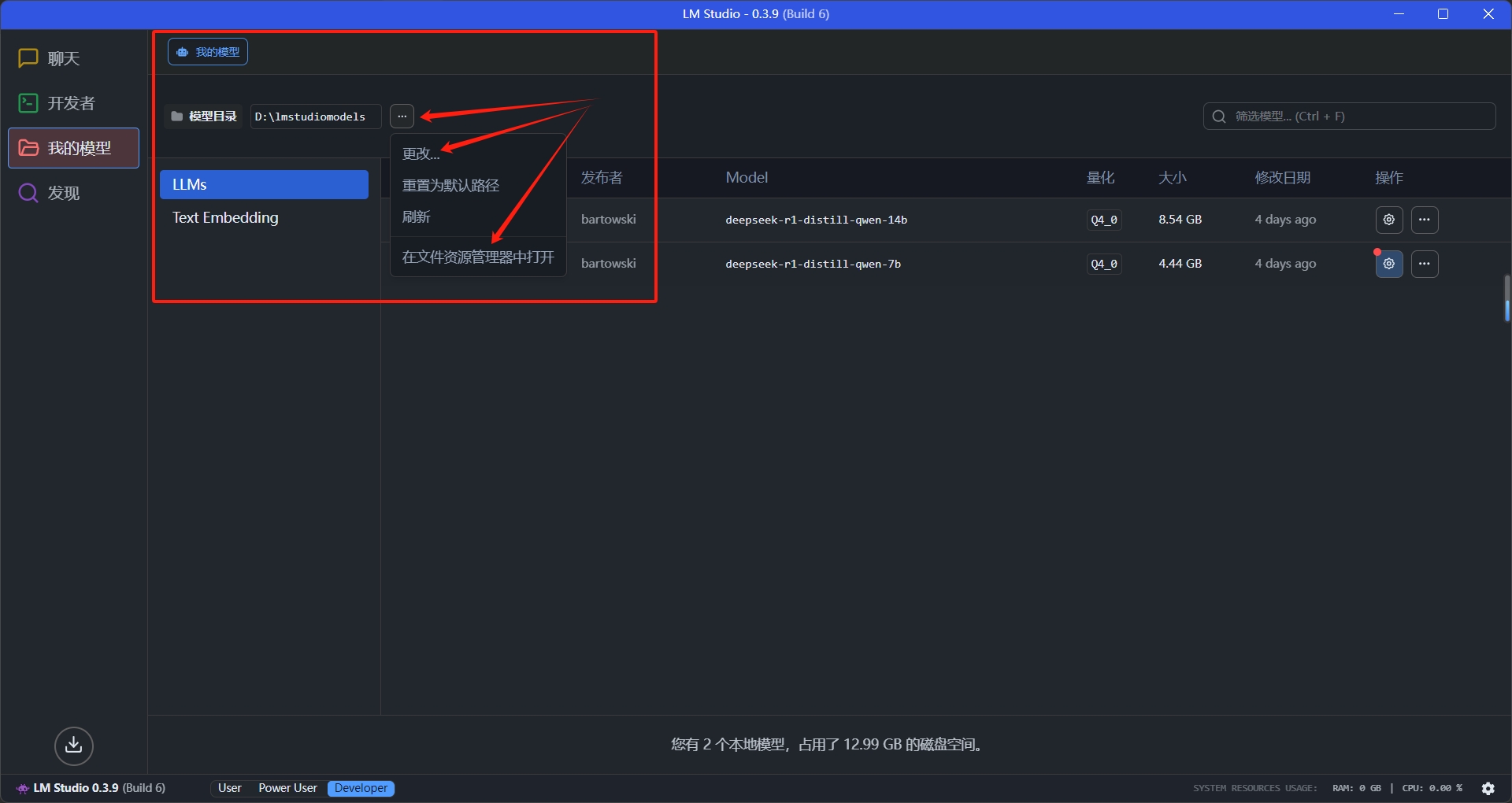
我们先打开我的模型,改一下模型存储位置
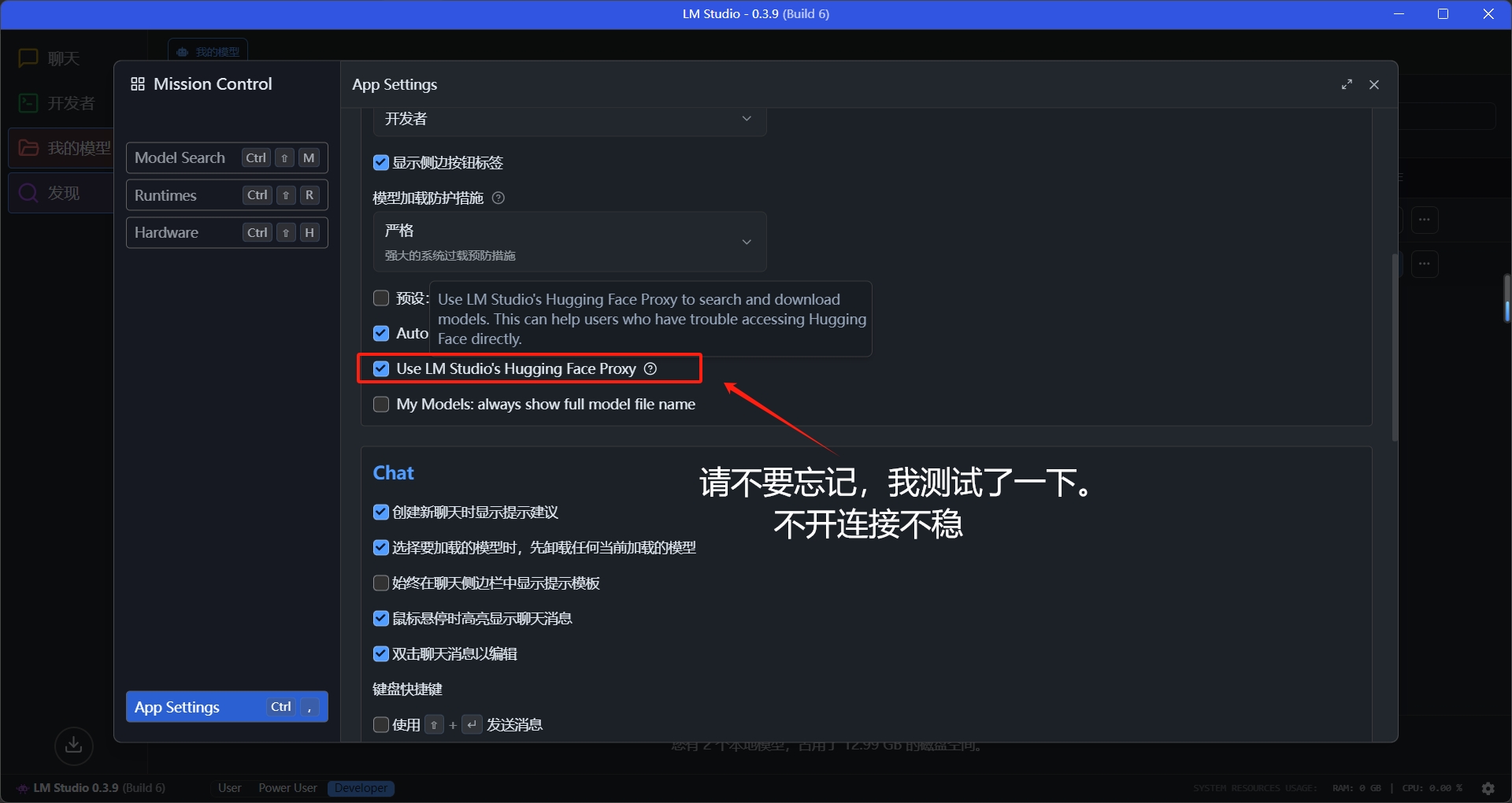
再打开发现页面,在这里我们需要修改部分设置:
1、切换语言为简体中文
2、打开LM自带的poxy,因为我们需要在代理的情况下,才能加载模型并且下载
现在我们可以开始着手下载模型了
打开ModelSearch,这里我们可以搜索一下DeepSeek R1,此时我们可以看到模型详情栏有很多选项
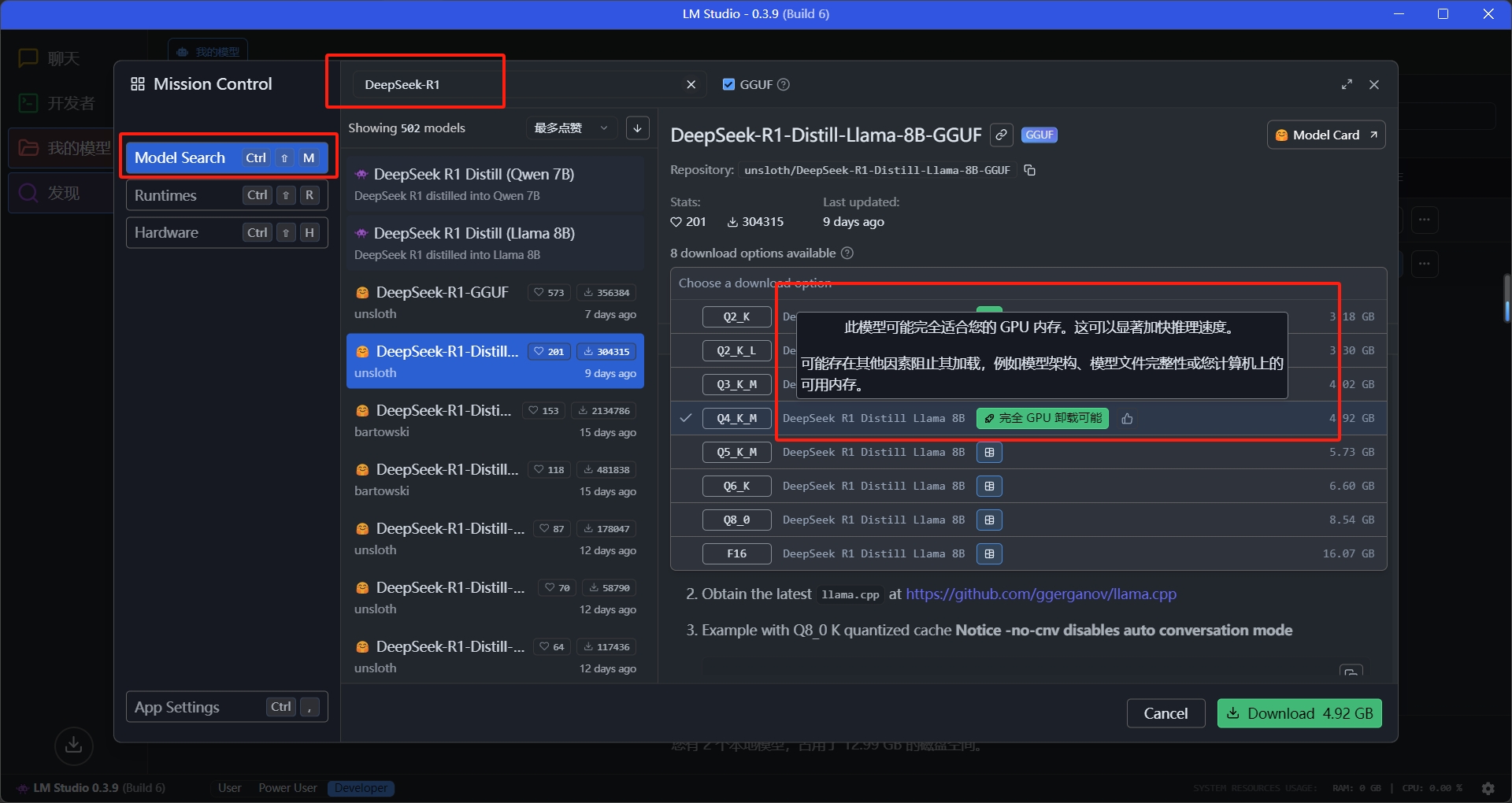

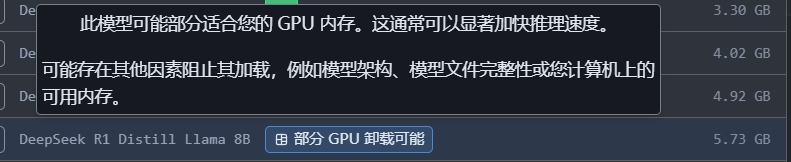

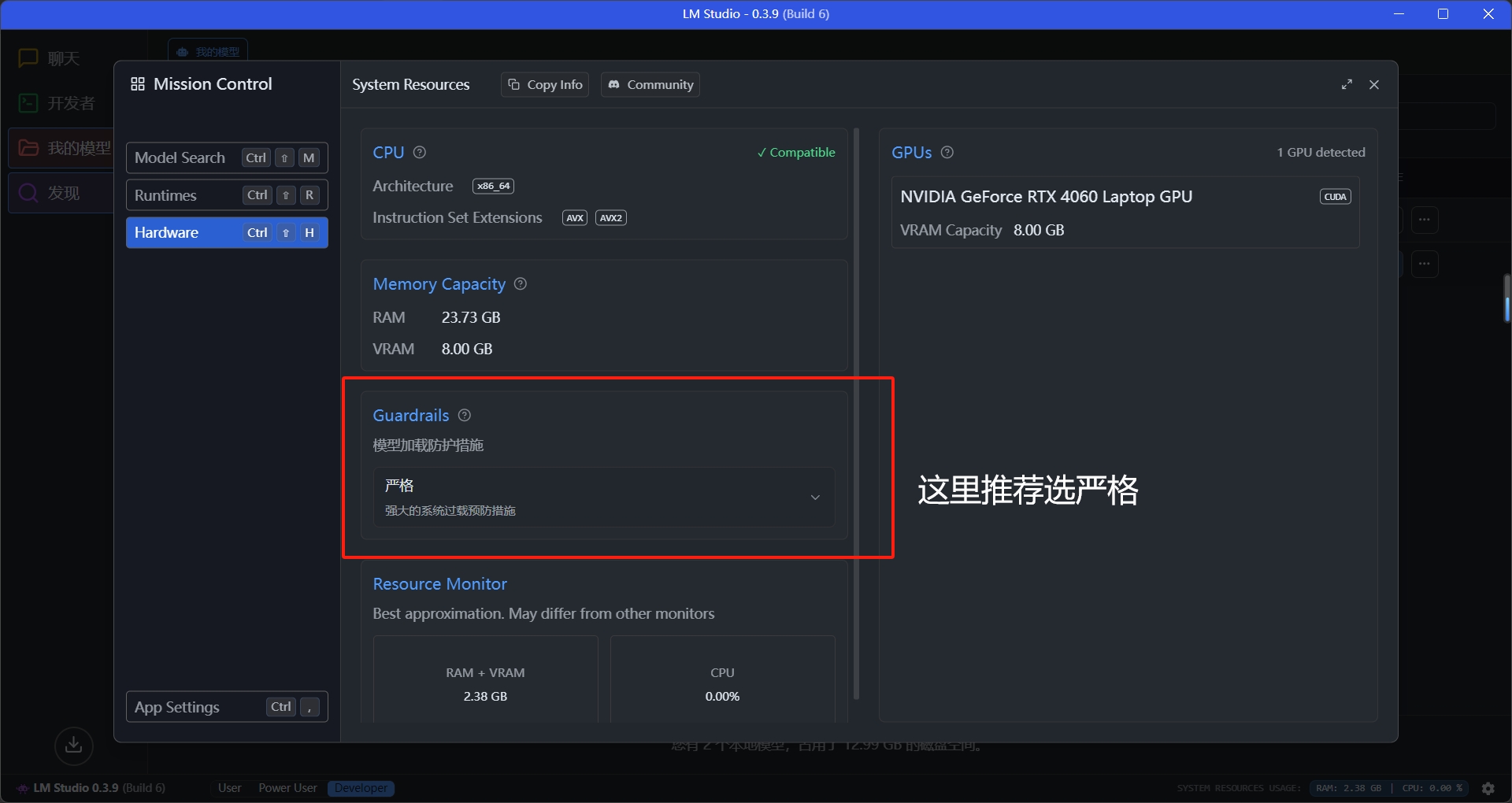
在选择模型版本时,请注意查看这些设备兼容性提示。LMStudio会根据您的硬件配置,标注哪些模型的量化版本适合你的设备。这个功能可以避免出现选择超出设备承载能力的模型版本的情况
所以请大家不要“勉强”自己的设备运行大参数的模型,哪怕运行起来,也不会有好的使用体验
了解模型量化版本:选择合适的模型变体
在开始下载之前,我们还需要理解模型文件名中量化参数的含义。从上面的截图中,我们可以看到诸如Q4_K_M、Q5_K_S这样的后缀。这些看似神秘的代号实际上代表了不同的量化配置方案。
量化(Quantization) 是一种通过降低模型参数精度来减少显存占用的技术。在文件名中,Q代表量化(Quantization),后面的数字表示比特数,而最后的字母组合则代表不同的量化策略:
Q2系列是最轻量级的量化版本,它使用2比特来存储权重,可以将模型尺寸压缩到最小,但相应的也会带来较大的性能损失。这个版本主要适用于设备极其受限的场景,或者对性能要求不高的测试环境。
Q3系列则是在Q2和Q4之间找到的一个平衡点,使用3比特存储权重,在保持相对较小文件体积的同时,试图减少性能损失。这个版本可以作为资源受限设备的一个较好选择。
Q4系列(如Q4_K_M、Q4_K_S)是目前最常用的量化版本之一。它使用4比特量化,在显存占用和模型性能之间取得了较好的平衡。其中K_M版本侧重性能表现,而K_S版本则进一步优化了显存占用。 Q5系列相比Q4提供更好的性能,显存占用适中,是性能和资源占用的另一个平衡点。
Q8系列保留了最多的原始精度,能够提供接近原始模型的性能,但相应地也需要更多的显存空间。
K_M和K_S这样的后缀则代表不同的量化算法优化策略,其中K_M版本通常在性能和资源占用之间取得较好的平衡,而K_S版本则进一步优化了显存占用,但可能会稍微影响模型性能。
理解这些参数对于选择合适的模型版本至关重要。建议根据自己设备的实际情况,优先考虑LMStudio界面中标记为"完全GPU卸载可能","部分GPU卸载可能"的版本。
闲话少说我们开始下载:
点击下载就行:
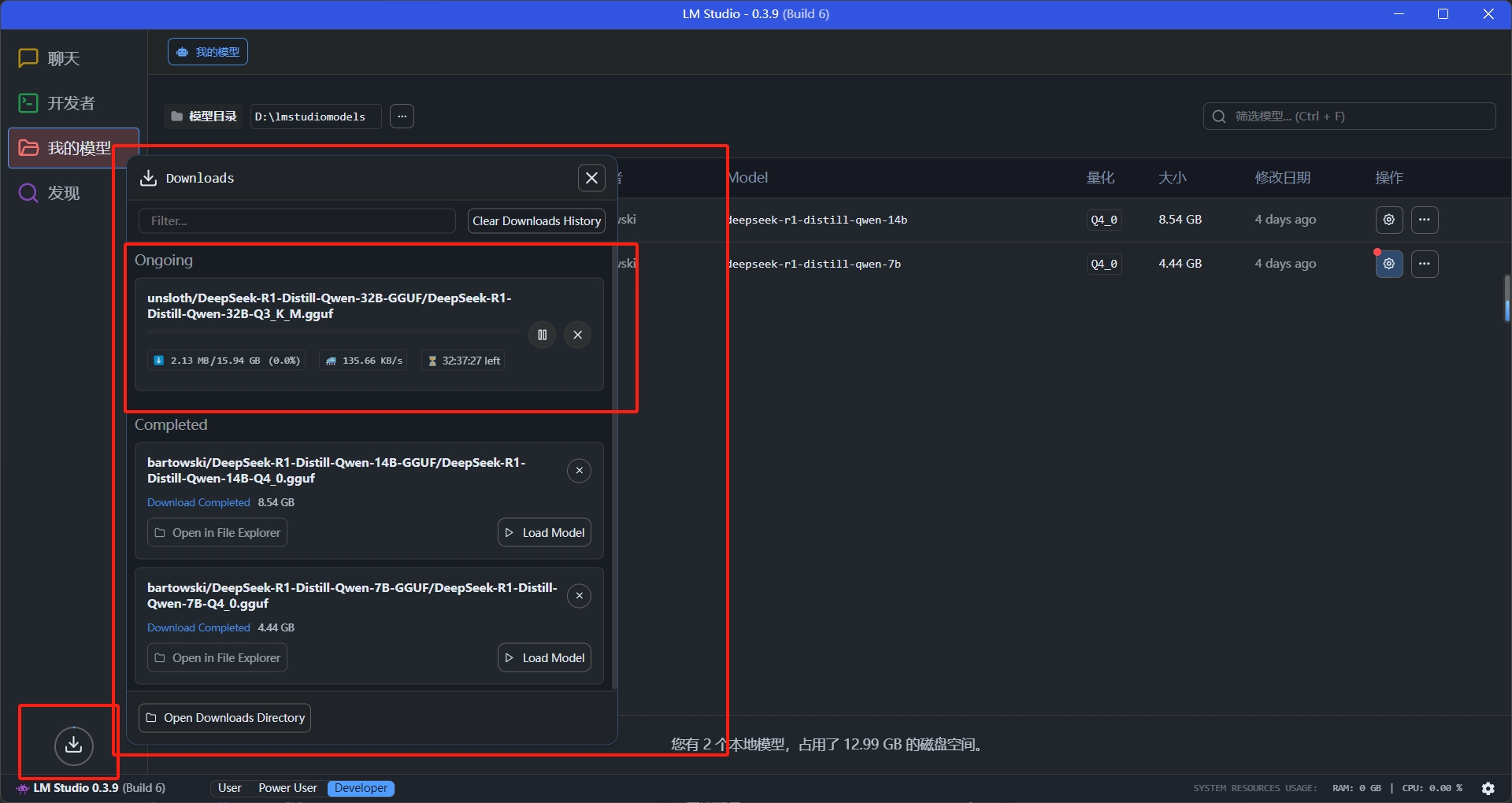
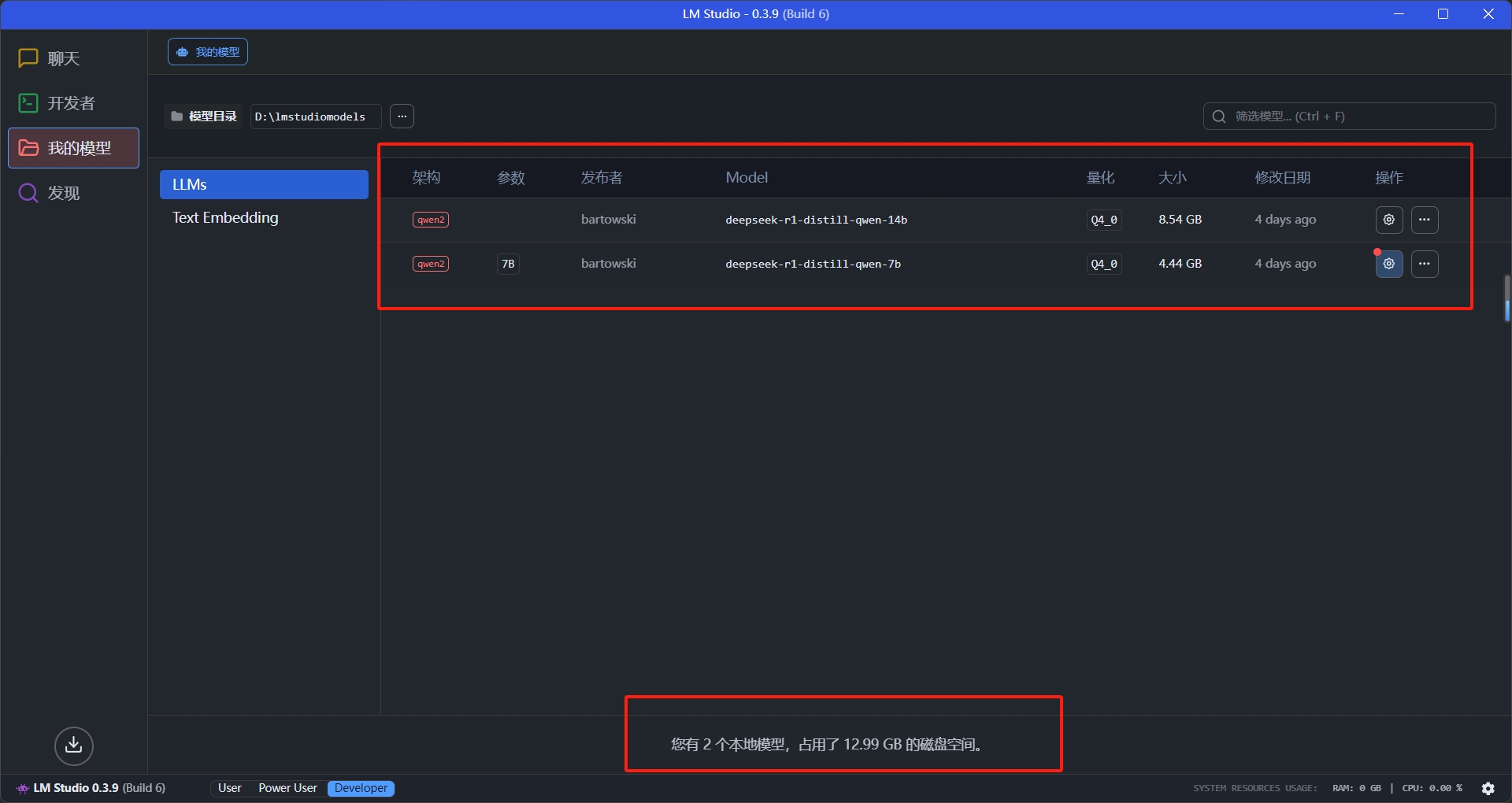
下载很简单,下载成功后就可以直接在模型界面看到下载好的模型
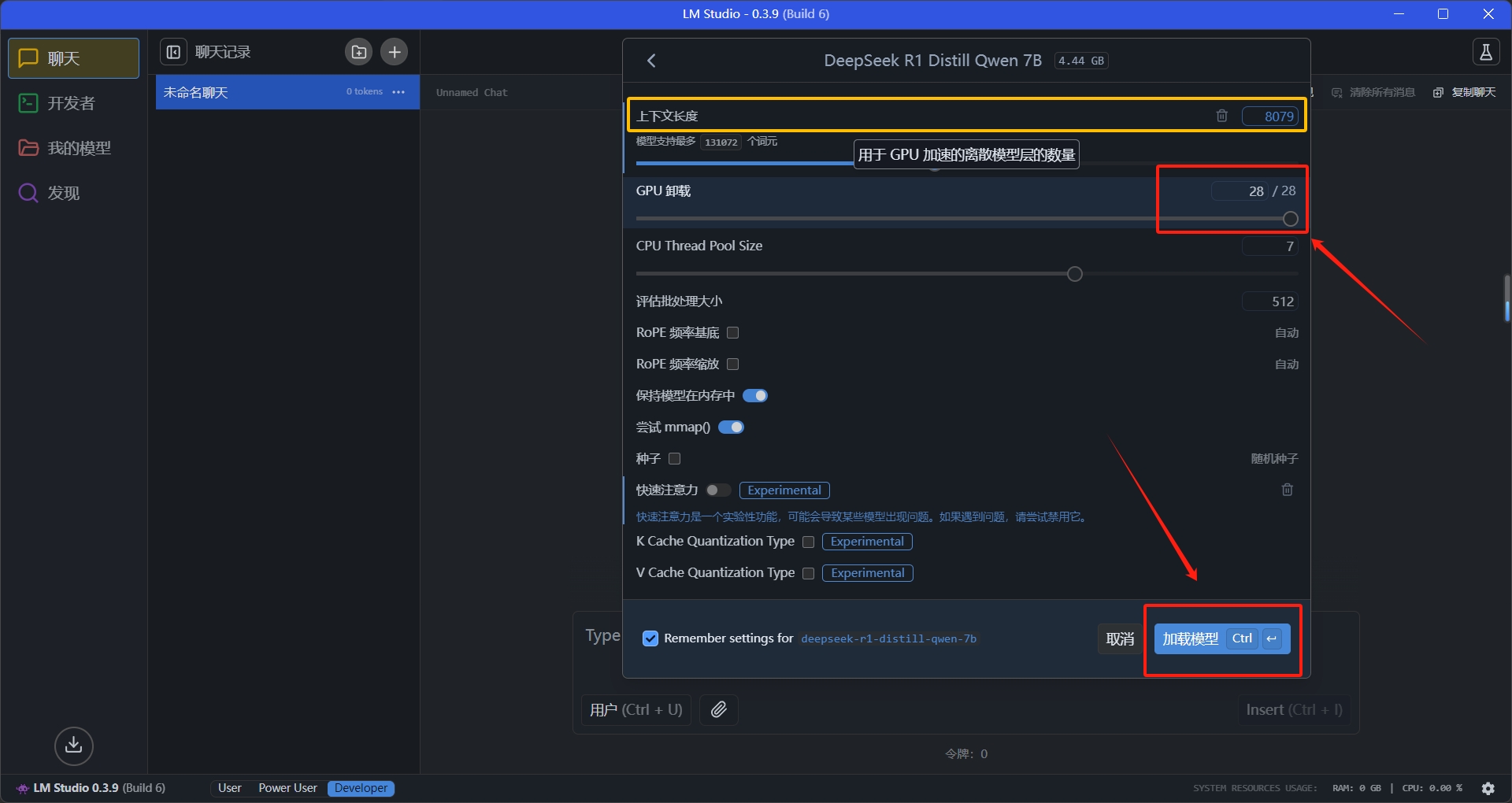
现在我们点开模型信息部分的设置按钮⚙
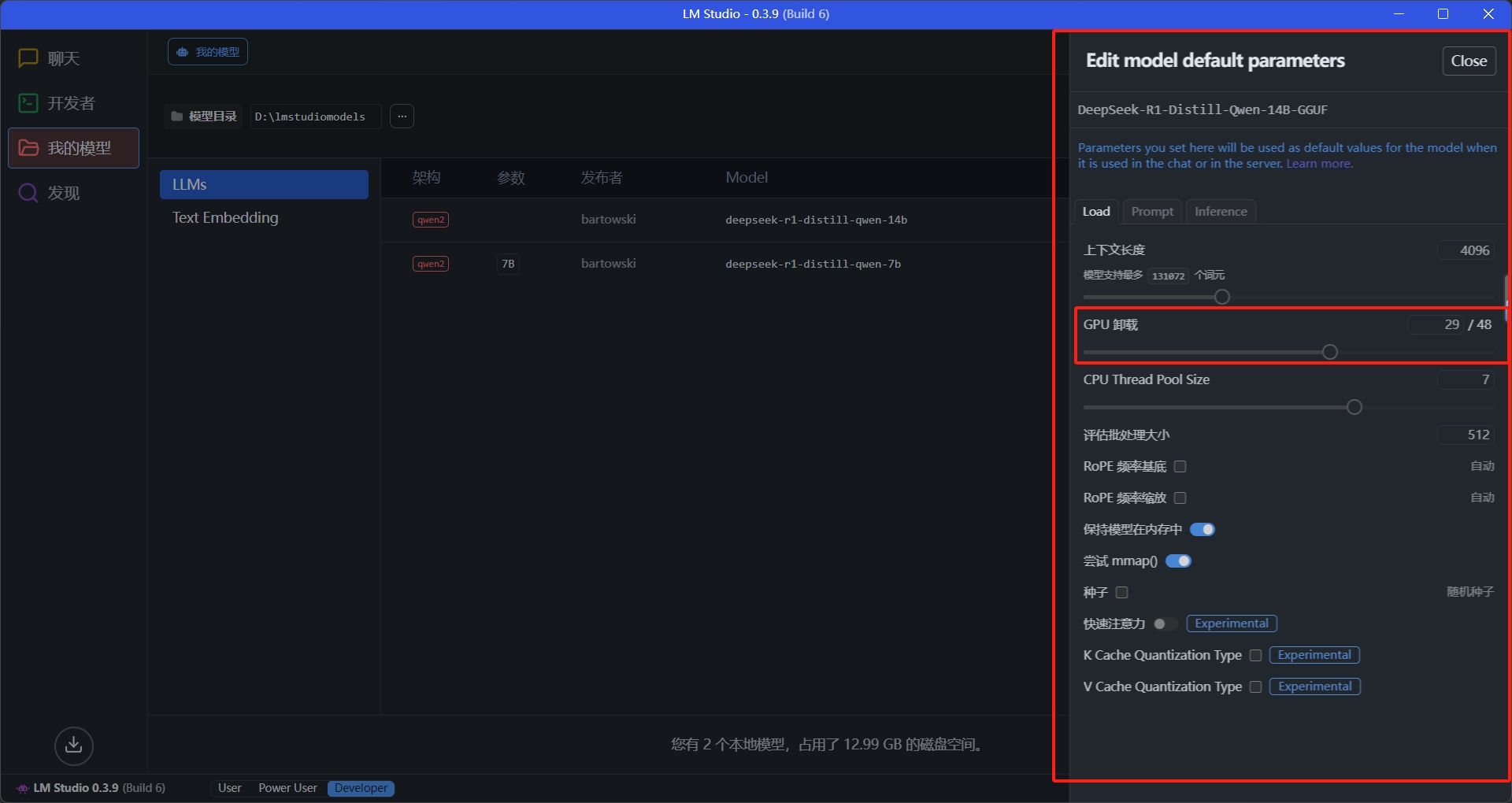
这里可以调节一些参数,理论上GPU卸载层数越多,运行速度越快
现在让我们回到对话界面,试试看
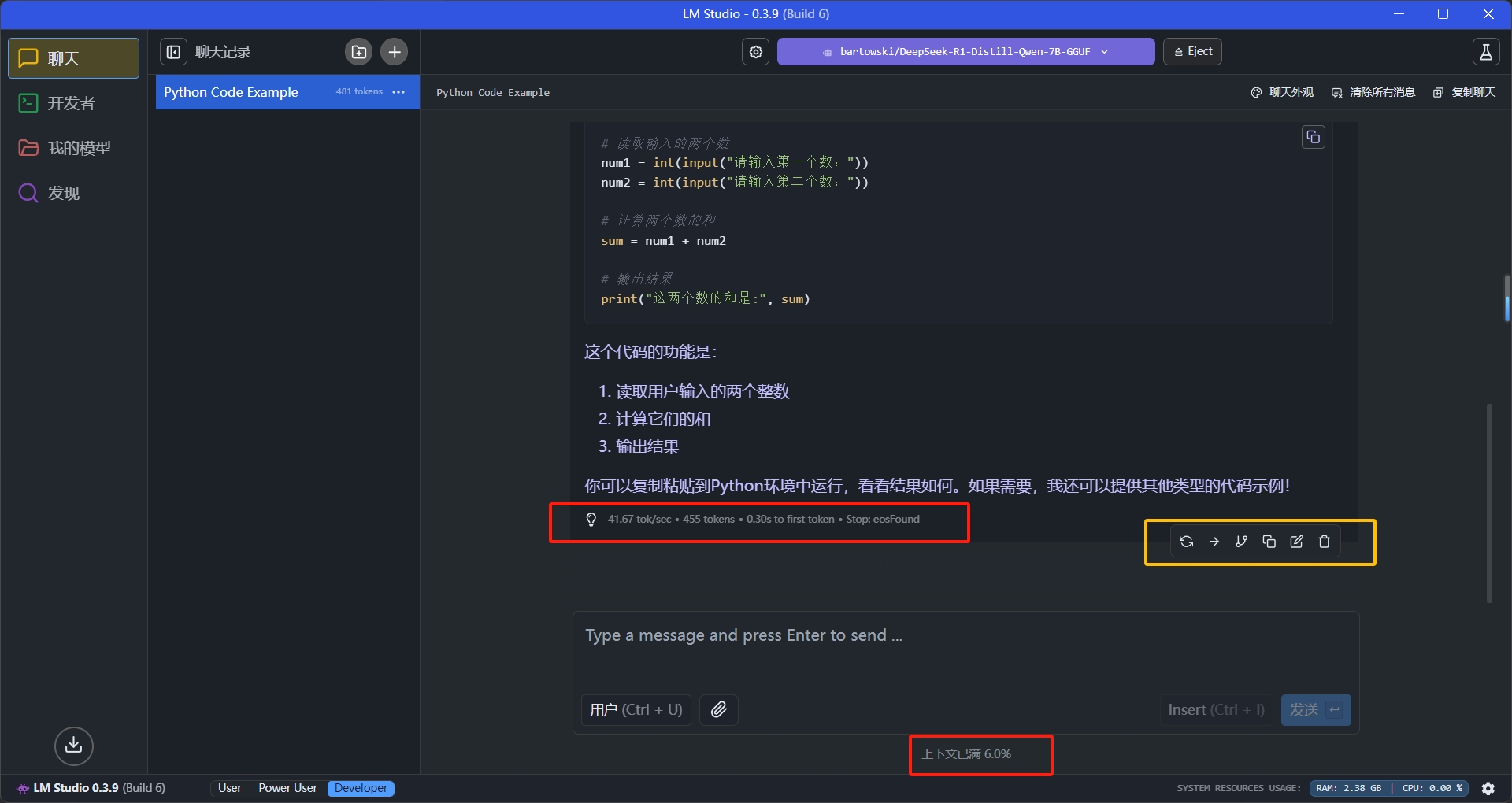
来问个问题:
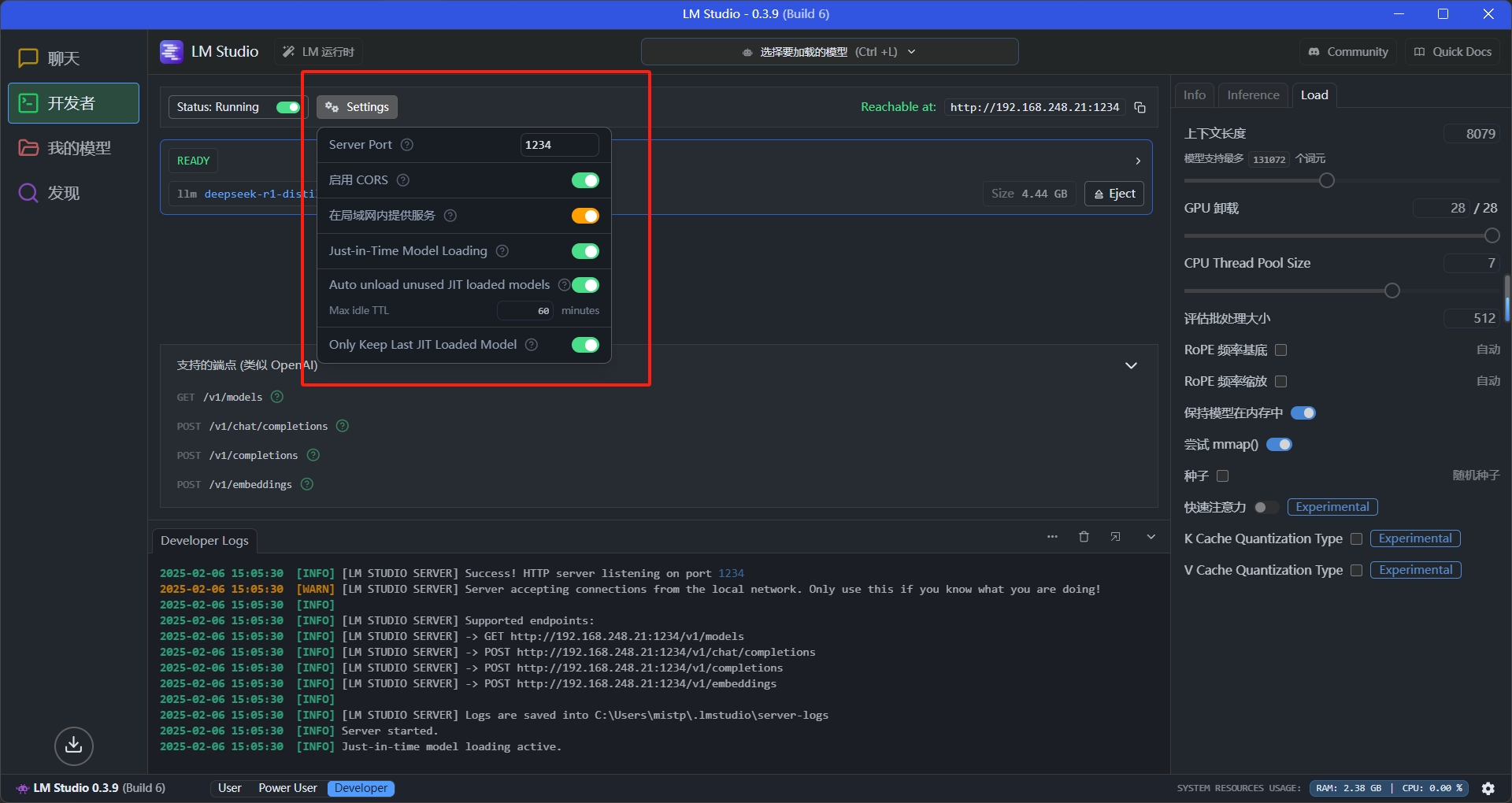
再来看看负责API服务的开发者界面
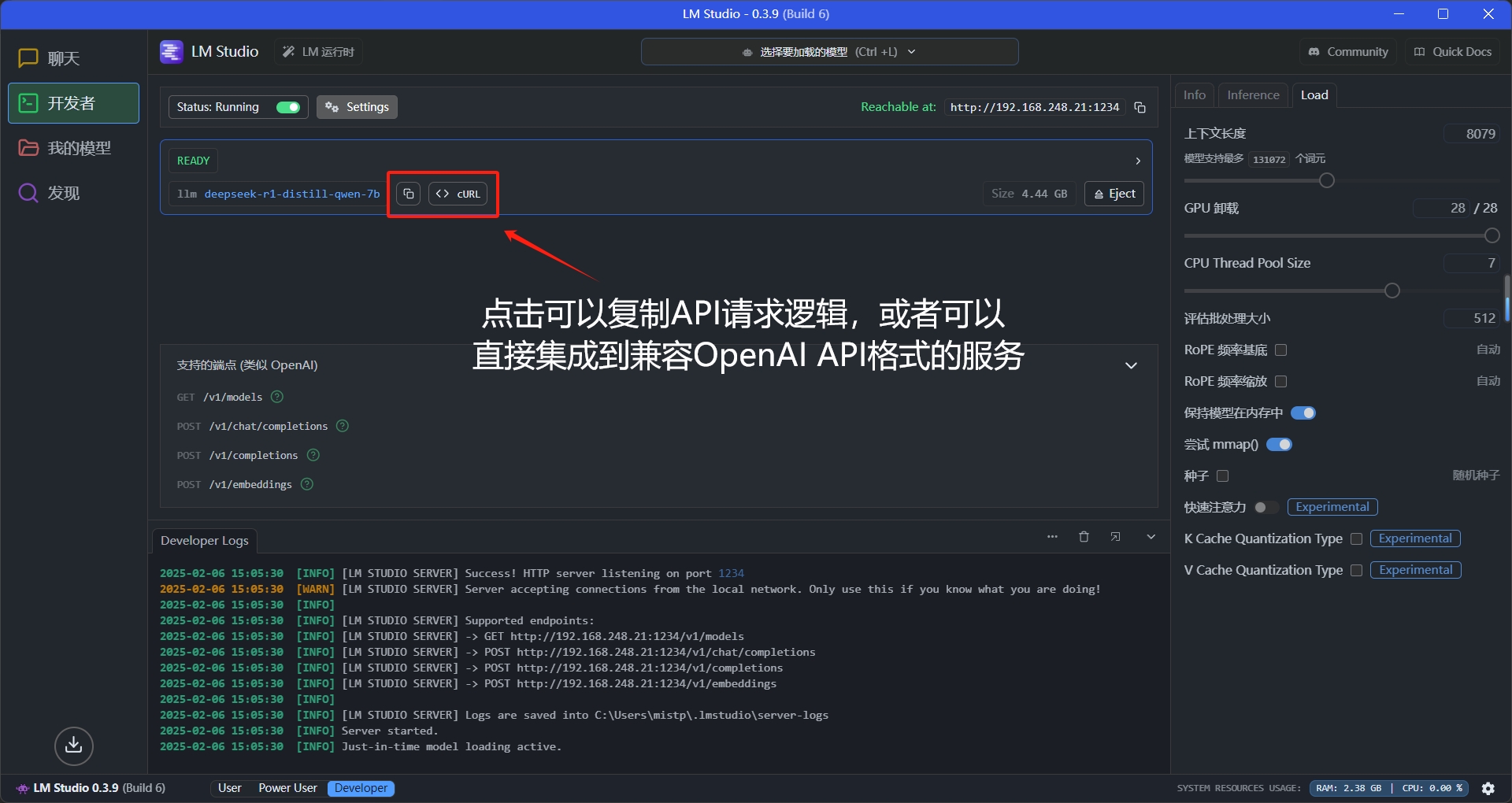
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1-distill-qwen-7b",
"messages": [
{ "role": "system", "content": "Always answer in rhymes. Today is Thursday" },
{ "role": "user", "content": "What day is it today?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": false
}'
接下来就靠自己摸索了,这里我简单贴剩下两个页面:
结语:回归技术本质,远离营销陷阱
通过这篇教程,我们学习了如何使用LMStudio部署DeepSeek-R1系列模型,但更重要的是理解什么是负责任的模型部署。从最初探讨的各类营销陷阱,到深入分析模型性能的真实表现,再到详细讲解量化版本的选择原则,我们始终围绕着一个核心理念:
技术创新的价值在于让AI更好地服务人类,而不是成为少数人牟利的工具。
DeepSeek-R1的开源发布确实代表了AI领域的一次重要突破,它展示了强化学习在大模型训练中的巨大潜力。但正如本文反复强调的,我们必须以理性和负责任的态度来对待这项技术。无论是选择合适的量化版本,还是关注设备的承载能力,都是为了确保我们能够可持续、健康地应用这项技术。
特别值得一提的是,LMStudio这样的工具为我们提供了一个理想的平衡点:它既保证了部署的便捷性,又充分考虑了设备的安全性。通过图形化界面和智能的硬件评估功能,它让更多人能够安全、理性地参与到AI技术的实践中来。
在结束之前,还有一点必须特别强调:本地部署模型的性能是有其固有局限的。无论我们如何优化部署方案,一个运行在本地的小参数模型,在短期内都不可能在性能上超越那些训练有素的千亿级参数大模型。DeepSeek-R1系列最可贵的价值在于其算法创新——展示了如何通过强化学习提升模型的推理能力,这为未来的模型训练指明了新的方向。但这种创新性并不等同于性能的绝对优势,我们必须以务实的态度来看待和使用这项技术。 最后,我想重申一点:
开源精神的核心是知识共享和技术普惠,而不是制造信息差和高门槛,更不能以服务大众之名行牟利之实。
希望这篇教程能够在前期帮助更多真正对AI技术感兴趣的学习者,在远离营销陷阱的同时,真正感受到技术创新带来的乐趣。
让我们共同维护一个理性、专业、互助的技术交流环境,让AI技术真正服务于每一个怀揣梦想的学习者。